유럽의 Liberal Arts&Science 모델을 접목한 학부 교양교육의 개선 가능성 탐색
Exploring Improvement Possibility of Undergraduate Liberal Arts Education Inspired by European Liberal Arts and Science Model
Article information
Abstract
한국 대학의 교양교육 개선을 위해 유럽의 University College[UC]에서 제공하는 Liberal Arts& Science[LAS] 프로그램의 특징을 분석할 필요가 있다. 유럽에서 LAS는 보편성, 학술성, 시대성이라는 현대 교양교육의 지향점을 반영하고 있어서 분과학문의 영향을 많이 받는 한국 교양 교육과정의 한계를 보완해 줄 수 있기 때문이다. 이 논문의 연구 목적은 유럽 UC의 LAS 모델이 한국 대학의 학부 교양교육 개선에 주는 시사점을 탐구하는 것이다. 이를 위해 유럽의 3개 학부대학 및 암스테르담 학부대학의 교과 요목, 이수 규정 등에 관한 텍스트 데이터를 수집하여 전처리한 후에 빈도 분석, 토픽 모델링, 의미연결망 등의 기법을 이용하여 분석하였다. 빈도 분석의 결과를 비교해서 14개의 공동 중심어를 추출하여 보편성 4개(social, human, public, development), 학술성 5개(research, science, knowledge, skills, analysis), 시대성 5개(international, global, contemporary, data, economic) 등으로 분류했다. 의미연결망 구조에서 보편성과 시대성 관련 주제어들은 여러 토픽에 포함되어 있었고 학술성 관련 주제어들은 연결도가 높았다. 암스테르담 학부대학의 교과목명 데이터에서 8개 토픽별 5개 주제어를 분석한 결과 226개 과목 중 Introduction이 포함된 과목이 18개였다. 융복합 성격의 입문 과목이 11개이고 주제 중심 과목이 7개이며, 하위 분과학문의 입문 과목 중심으로 구성된 한국 대학의 교양교육 개선에 시사하는 바가 크다. 운영 및 이수 관련 텍스트 분석을 토대로 전담 교수제 도입, 융복합 교과목 편성, 지도교수 역할 강화, 교수-학습법 개발 등을 확인하였다. 텍스트 데이터 분석 기반의 이러한 논의 결과는 한국 교양교육의 표준모델 개선 또는 각 대학의 교양교육 개편에 활용할 수 있을 것이다. 한국 대학에서 교양교육 전담기관, 학부대학, 자유전공학부 등의 교양교육 프로그램을 개발하고 운영할 때도 참고할 수 있을 것이다.
Trans Abstract
In order to improve liberal arts education in Korean universities, it is necessary to analyze the characteristics of European Liberal Arts & Science [LAS] programs. This is because LAS in Europe reflects the orientation of modern liberal arts education such as universal, academic, and contemporary property, and can supplement the limitations of the Korean liberal arts curriculum, which is heavily influenced by sub-disciplines. The purpose of this paper is to explore the implications of the European University College [UC]s’ Liberal Arts & Science model for undergraduate liberal arts education in Korean universities. To this end, text data of three European UCs and Amsterdam UC [AUC] were collected, preprocessed, and then analyzed using techniques such as frequency analysis, topic modeling, and a semantic network. By comparing the results of the frequency analysis, 14 common keywords were extracted and classified into universal (social, human, public, development), academic (research, science, knowledge, skills, analysis), and contemporary (international, global, contemporary, data, economic) orientation. In the structure of the semantic network, some keywords were assigned in several topics. As a result of analyzing 5 keywords of 8 topics in the course titled Data of AUC LAS, 18 of 226 courses included an Introduction. 11 of them are introductory courses of convergence and 7 are theme-oriented courses, which is different from the cases in Korea, which are mostly focused on introductory courses in sub-disciplines. Based on the analysis of texts of AUC LAS, this paper proposes three things: the introduction of a coordinator system and convergence courses, the strengthening of the role of advisors, and the development of teaching-learning methods. The results of these discussions based on text data analysis can be used to improve the standards of liberal arts education in Korea or to reorganize liberal arts education at each university. They can also be used as a reference when developing and managing educational programs such as in institutions dedicated to liberal arts education, university colleges, and departments for self-designing curriculum at Korean universities.
1. 서론
한국 교양교육의 중요한 문제 중의 하나는 교양교육의 지향점으로 언급될 수 있는 보편성, 학술성, 시대성을 반영한 개선이 쉽지 않다는 점이다(정승원 외, 2020). 이는 기존의 학과나 전공에 소속된 교수진으로 구성된 협의체 또는 임기제 기관장의 신념에 따라 교양교육의 운영 방향이 좌우되는 경우가 많기 때문이다. 전통적으로 미국의 교양교육 모델에 영향을 많이 받은 교양 교과과정에 편성된 교과목도 기존의 단과대학이나 학과를 중심으로 구성되는 측면이 있어서 학생들의 자율적인 선택에 제한이 있거나 시대의 흐름을 반영하지 못하는 경향이 있다. 특히 교양교육의 중심을 이루는 기초학문 분야의 학과들이 있는 종합대학에서 이러한 현상은 두드러진다. 그러다 보니 대학별로 교양교육의 범위와 질의 차원에서 간극이 발생할 수 있어서 최근에는 교양교육 중심의 공유대학에 대한 논의도 이루어지고 있다(이보경, 2023). 해당 논문에서는 미국 대학의 과목 개방과 학점 이전 및 유럽 대학의 UC에서 재부상하고 있는 Liberal Arts & Science1) 등이 언급되고 있다. 이 논문에서는 유럽 UC의 LAS 교육에 관련된 텍스트 데이터를 데이터 과학의 기법을 이용하여 분석함으로써, 한국 대학의 미래형 교양교육 개선을 위한 이론적이고 실제적인 정보를 제공하고자 한다. 유럽 UC의 LAS 교육이 보편성, 학술성, 시대성을 한국의 경우보다 더 먼저 반영한 것으로 판단하기 때문이다.
유럽에서 LAS는 학사 수준의 교육에 대한 구체적인 접근 방식이며, 분과학문 중심의 교육 프로그램의 단점을 극복하기 위한 대안으로 제공되고 있다. LAS의 특징 중 하나는 학생 스스로 학제적 커리큘럼을 설계하는 것이다. LAS 교육의 목적은 폭넓은 지식과 스킬을 개발하여 삶과 직업 생활에서 직면할 수 있는 문제들에 적용할 수 있는 능력을 함양하는 것이다(LAS at Freiburg UC). LAS는 문제가 더 복잡해지는 시대에 성공적인 사회생활과 의미 있는 삶을 살기 위해 더욱 중요한 교양교육을 위한 유럽 대학의 노력인 셈이다. LAS 교육을 통해 다양한 학문 분야의 지식을 습득하여 당면한 사안에 대한 독특한 시각을 가지고 복잡한 문제를 창의적으로 해결할 수 있는 능력을 함양할 수 있기 때문이다. 특히 자기 주도적 학습능력이 중요한 시대에 학생 자신의 학습 프로그램을 설계할 때 상당한 자유를 부여하는 유럽의 LAS 교육 모델을 한국 대학의 교양교육 개선 또는 자유전공학부의 교육과정에 접목할 수 있다.
이 논문의 연구 목적은 유럽의 LAS 모델을 한국 대학의 학부 교양교육의 개선에 접목하는 가능성을 탐색하는 것이다. 이러한 목적을 달성하기 위해 유럽의 일부 UC에서 제공하는 교과 요목, 이수 규정 등에 관한 데이터를 이용한다. 데이터의 텍스트 마이닝을 위해 토픽 모델링과 의미연결망 분석이라는 방법을 활용한다. 유럽 모델의 특징을 분석하여 이를 한국 대학의 교양 교육 개선에 연계하는 방안을 논의하기 위해서이다. 이러한 논의를 통해 한국 교양교육의 표준모델 개선 또는 각 대학의 교양교육 개편에 활용할 수 있는 정보를 제공하고자 한다. 대학에서 교양교육을 전담하는 기관이나 학부대학은 물론이고 다양한 방식의 교양교육 실천이 가능한 자유전공학부의 교양교육 프로그램을 개발하고 운영하는 데 활용할 수 있을 것이다.
2. 선행 연구
유럽의 전통적인 교양교육은 고대부터 형성되어 중세에 진화하였고(송성수, 2022, p. 45), 르네상스와 계몽주의 시대를 거치면서 발전했다. 19세기에 전문적이고 연구 지향적인 대학의 출현으로 퇴조의 기미를 보였으나(박병철, 2018, p. 49; 조효제, 2013, p. 198), 근래에 유럽의 일부 국가에서 교양교육에 대한 관심이 증가하면서 UC를 중심으로 하는 LAS 교육이 부활하고 있다(Abrahám, 2018; Boetsch, et al., 2015; Jenainati et al., 2017; van der Wende, 2011). UC는 지역이나 나라에 따라 제도 및 운영 시스템이 다르다. 유럽 내에서도 설립 취지나 시기에서 차이가 있다. 예를 들어 영국에서 UC London이나 UC Oxford 등 모체가 되는 대학의 역사는 13세기로 거슬러 올라간다. 네덜란드에서는 UC Utrecht는 Utrecht University의 일부로 도입되었는데, 이 종합대학은 1636년에 설립되었다. 네덜란드 UC의 LAS는 길지 않은 역사에도 불구하고 사회나 졸업생의 평판이 높은 편이다(ROA, 2018, p. 6).
한국에서 이전의 외국 교양교육에 관한 국내의 선행연구들은 미국과 아시아 등 특정 지역의 사례를 다루는 경우가 많다. 국내 특정 대학의 사례를 주제로 한 연구도 있다. 이러한 연구들은 연구방법에서도 특징을 볼 수 있는데, 주로 문헌 검토 또는 모집단이 아니라 표본을 대상으로 실시한 설문 등을 활용한다는 점이다. 물론 국내 대학의 사례를 연구한 경우에 해당 대학의 전체 데이터를 사용하기도 하나, 대체로 일부 구성원을 대상으로 하는 경우가 적지 않다. 신기술의 발전으로 새로운 분석 기법이나 도구들을 이용하여 대규모 데이터를 분석의 대상으로 삼는 다른 분야의 흐름을 고려하면 교양교육 분야에서도 이러한 방식의 연구를 도입할 필요가 있다. 이전의 분석 방법으로 해결하기 어려운 문제를 새로운 방법론의 도입을 통해 해결할 가능성이 있기 때문이다.
국내 교양교육 연구에서 외국의 특정 국가를 대상으로 연구한 논문 및 국내 대학 대상의 연구에서 다룬 주제의 일부를 <표 1>에서 정리하였다.

국내 교양교육 연구에서 다룬 국내외 사례 주제
이전 연구에서는 외국의 사례 중 미국이나 중국, 일본 등 아시아의 교양교육에 치우친 측면이 있다. 국내 대학의 교양교육에 관한 연구에서도 특정 대학의 사례 중심으로 연구되고 있다.
특정 지역과 대학 중심 연구와 더불어 유럽의 LAS 모델을 살펴보고 이를 국내 대학의 교양교육 개선에 접목할 가능성을 논의할 필요가 있다. 특정 지역의 사례만으로는 보편성과 시대성 및 글로벌 환경에 대처하지 못할 수도 있기 때문이다. 물론 근래에 유럽의 교양교육에 관한 논문이 발표되어, 영국의 일부 대학에서 개설하고 있는 미국식 Liberal Arts의 현황과 함의점을 논의한 바 있다(김향숙, 최진실, 2019). 프랑스 교양교육의 역사와 이념에 관한 논문도 발표되었으며, 대학 교양교육의 기원에서 출발하여 재편 과정에서 나타난 기본 정신 및 원칙에 대해 논의하고 있다(이기라, 2015).
이전의 연구들이 비해 최근에는 새로운 기법을 활용한 연구가 있다. 교양교육 관련 연구에서도 최근에 예를 들어 토픽 모델링을 이용한 논문이 발표되었다(유정민, 이경자, 2023). 이를 포함하여 근래에 발표된 일부 논문의 내용을 <표 2>에 요약하였다.

최신 기술을 활용한 교양교육 관련 논문의 주요 내용
2020년대 이후에 이러한 방식의 연구가 수행된 것을 볼 수 있다. 6년, 10년, 20년 사이의 논문을 대상으로 초록에서 주제어를 추출하거나 연구자가 제시하는 핵심어를 활용하는 경우가 주류를 형성하고 있다. 분석 방법은 주로 LDA 토픽 모델링이 사용되고 있으며 네트워크 분석과 중심성 분석을 병행하는 연구도 있다. 토픽 모델링을 위해 서지정보와 영문초록 데이터를 사용한 연구도 있다. 분석을 위해 국내에서 개발된 특정 도구를 선호하는 경향이 있다. 토픽 모델링에서 토픽 수 지정의 과정에 관해 설명한 경우는 많지 않다.
이상의 이론적 배경 및 선행 연구 검토를 토대로 이 논문에서 다루고자 하는 연구 문제는 다음과 같다.
① 유럽 UC의 LAS 이수 설명에서 많이 출현하는 핵심어는 무엇인가?
② Amsterdam UC[AUC] LAS 교과 요목의 주요 토픽 및 중심어는 무엇인가?
③ 유럽 LAS 교육이 한국의 교양 교육과정 개선에 시사하는 점은 무엇인가?
이를 위해 앞에서 살펴본 선행연구를 참고하여 텍스트 마이닝 기법을 사용한 텍스트 데이터 분석을 시도한다. 물론 이러한 방식으로 도출된 결과가 절대적인 가치를 지니는 것은 아니지만, 규모가 큰 데이터에서 토픽이나 주제어를 파악하는 데 유용할 수 있기 때문이다.
3. 연구 방법
분석 대상 데이터를 유럽 일부 UC의 LAS 운영 관련 텍스트 및 특정 대학의 교과 요목으로 한정한다. 많은 대학의 데이터를 처리하기에는 시간과 비용이 너무 많이 소요되기 때문이다. 먼저 유럽 및 AUC의 PDF 형식 텍스트 데이터를 수집하여 파이썬으로 전처리하였다. 정제된 데이터를 사용하여 단어 빈도를 보여주는 파이썬과 오렌지 워드 클라우드 및 네트워크 시각화를 통해 결과를 제시한다. AUC의 LAS 데이터를 사용하여 LSA와 LDA 토픽 모델링 알고리듬으로 토픽 및 중심어를 추출하여 시각화하고 설명한다. 의미연결망 구조를 통해 각 토픽에 포함되는 주제어 사이의 의미적 관계를 알아보고 지향성을 기준으로 분류해 본다.
3.1. 데이터 전처리 및 빈도 분석
유럽에는 영국 등 여러 나라에서 LAS 프로그램을 운영하고 있으며, LAS 협의체(European Consortium of Liberal Arts and Sciences[ECOLAS])의 회원교만 26개2),이다(ECOLAS). 네덜란드의 경우 나라 규모에 비해 UC가 많은 편이며, 한 자료에 의하면 회원교로 등록하지 않은 대학을 포함하여 9개교이다(UC in the Netherlands). 그 가운데 네덜란드의 대표적인 UC인 Amsterdam University College [AUC], Erasmus University College[EUC], Maastricht University College[MUC]와 독일의 Freiburg University College[FUC]의 LAS 관련 텍스트를 데이터로 사용한다. 네덜란드와 독일은 유럽에서 LAS 분야에서 선도적인 역할을 하고 있기 때문이다(Jenainati et al., 2017; Dekker, 2018, p. 87).
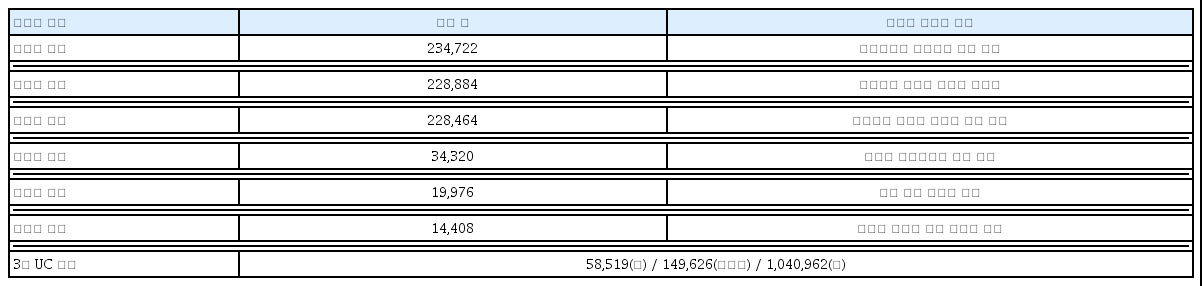
유럽 UC의 LAS에서 중심어를 찾기 위해 EUC, MUC, FUC 등 3개 대학의 텍스트를 통합한 데이터로 빈도 분석을 하고 이를 시각화한다. AUC LAS 운영에서 주요 토픽과 중심어를 찾기 위해 AUC에서 제공하는 LAS 관련 교과목의 설명 텍스트를 사용하여 토픽 모델링을 수행하여 토픽별 중심어들의 의미연결망 구조를 생성한다. AUC의 LAS는 세계적으로 잘 알려져 있기도 하고(van der Wende, 2011; Boetsch, et al., 2015), 운영 관련 텍스트인 Academic Standards and Procedures 2022-2023[ASP]를 제공하고 있어서 논의를 전개하기에 유용하기 때문이다. 통합 데이터는 435쪽 분량의 텍스트이며, 원 데이터를 전처리하여 주로 빈도 분석을 위해 사용한다. AUC LAS의 텍스트는 192쪽 분량의 데이터로 226개 교과목을 설명하는 내용이다. 토픽 모델링을 위해 PDF 파일을 CSV 파일로 변환하였으며 변환 과정에서 문서들의 크기를 맞추기 위해 20줄 이상의 정보는 제거하여 균형을 맞추었다. 이 데이터가 분석의 중심이라서 이를 중심으로 전처리 과정을 설명하고 통합 데이터 관련 내용을 요약한다.
분석의 중심인 AUC 텍스트의 전처리 과정에서 추출한 단어 수는 <표 3>에서 비교적 상세하게 정리하였으며, 3개 UC 통합 데이터의 경우는 맨 아래에 약식으로 제시하였다.
Amsterdam University College Liberal Arts&Science 텍스트의 전처리 과정
전처리 과정에서 파일 형식의 데이터로부터 텍스트를 추출하는 tika를 사용하여 파싱(parsing) 처리하였으며, 정규 표현식을 이용하여 공백, 숫자, 부호 등을 제거하였다. 정규화를 위해 lower 함수를 이용하여 모든 문자를 소문자로 변경하였다. 파이썬 프로그램에서는 영어의 경우 같은 단어라도 대문자와 소문자를 다르게 인식하기 때문이다. 문장의 단어들을 추출하기 위해 nltk의 tokenizer 함수로 토큰화를 수행하였다.
빈도 분석을 위해 3개 UC 통합 데이터에서는 전처리하기 전 문장 내의 1,040,962개 단어를 토큰화한 후 149,626개의 토큰을 추출하였다. 불용어 처리 후에 분석 대상으로 삼은 단어의 수는 58,519개이다. AUC 데이터에서는 공백 제거 후의 234,722개 단어를 전처리하여 추출한 14,408개의 단어가 분석의 대상이다. 추출된 단어들의 빈도를 분석하기 위해 Counter 모듈을 사용하였고, 출현 빈도가 높은 15개 단어에 대한 시각화를 위해 WordCloud를 사용하였다.
3.2. 의미연결망 구성
의미연결망 분석은 비정형 텍스트 데이터에서 단어를 추출하고 단어의 문서 내 등장 빈도를 측정하여 시각화하는 분석 기법이다. 이 논문에서는 의미연결망 구조를 만들어 의미적 관계를 살펴보고자 한다. 의미연결망 분석의 장점은 비정형 데이터인 텍스트를 네트워크를 통해 시각적으로 볼 수 있다는 점이다. 이 논문에서 의미연결망 구성을 함께 보는 이유는 토픽별 주제어들의 세부 내용을 유기적인 맥락에서 이해하는 데 유용하기 때문이다(임수민 외, 2020, p. 13). 다시 말해 의미연결망을 구성하는 노드 사이의 의미를 해석하여 양적인 측면과 더불어 질적인 측면에서 데이터에 접근할 수 있기 때문이다(손복은, 전대일, 2020, p. 100). 한편 Gerlach 등(2018)은 LDA 알고리듬을 비판하기도 한다. 문서 모음의 잠재적인 토픽 구조를 유추하는 접근법인 LDA의 범용성에도 불구하고 확률과 통계를 기반으로 한다는 점과 토픽 수를 결정하는 것이 어렵다는 점을 이유로 들고 있다(Gerlach et al., 2018, p. 8). 이 연구자들은 현대의 주요 과제 중 하나가 구조화되지 않은 텍스트에서 유용한 정보를 추출하는 것이라고 강조하면서, 토픽 모델링과 더불어 의미연결망 분석을 함께 활용하는 방법을 대안으로 제시하고 있다.
의미연결망 분석(Semantic Network Analysis[SNA])은 각 토픽에 포함된 주제어 간의 동시 출현을 기준으로 네트워크를 구성하여 단어들의 의미적 연결을 분석하는 방법이다(고지민, 박한샘, 2020, p. 849). 이를 위해 각 토픽의 주제어를 점(node)으로 표시하고 점들 사이의 관련성을 선(link)으로 표현하여 각 주제어가 어떤 방식으로 연관되어 있는지 분석할 수 있다(임수민 외, 2020, p. 13). 이러한 아이디어는 네트워크 과학에서 도입하였으며,3,) 특히 사회 연결망 분석(Social Network Analysis)에 많이 활용되고 있다(손승우 외, 2022, p. 24). 텍스트 마이닝에서도 문서의 토픽에 포함되는 주제어 사이의 연결을 의미적으로 분석하기 위해 활용한다. 이 논문에서는 토픽별 주제어를 이용하여 의미연결망 구조를 시각화하였으며, 주제어간 의미적 관계를 간단히 살펴보았다.
3.3. 토픽 모델링
토픽 모델링이란 문서들의 집합에서 토픽을 추출하는 방법이며, 구조화되지 않은 대규모 텍스트를 분석하여 숨겨져 있는 주제 구조를 발견하고 범주화하는 통계적 추론 알고리즘이다(손복은, 전대일, 2020, p. 100). 토픽 모델링(Topic Modeling[TM])은 문서 모음에서 기저의 토픽들을 발견하려고 시도하는 일종의 텍스트 마이닝 기법이며, 대규모 텍스트 말뭉치를 마이닝할 때 성공적으로 사용되고 있다(Blei et al., 2003). 이 논문에서 토픽 모델링을 위해 사용하는 알고리듬은 LSA와4), LDA5),이다. 대수학의 원리를 적용하는 LSA는 문서-용어 행렬을 분해한 후 근사하는 값을 찾는 방식이다. 견고한 통계적 기반을 제공하지 않는다는 단점에도 불구하고 이 알고리듬들을 사용하는 이유는 간단하면서도 직관적으로 이해하기 쉽고 계산이 비교적 효율적이기 때문이다(Abdelrazek et al., 2023, p. 4). 베이지안 확률의 원리를 적용하는 LDA 알고리듬을 사용하는 까닭은 과정이 비교적 단순해서 확장 및 해석 가능성이 높기 때문이다.6)
토픽 모델링을 사용하는 다른 이유는 텍스트 데이터 내 단어들의 빈도수를 통계적으로 분석하여 전체 데이터에서 잠재적 주제인 토픽들을 자동으로 추출하여 분류한다는 점에서 문서들의 토픽 분석 시 유용하기 때문이다(손복은, 전대일, 2020, p. 100). 특히 LDA 모델이 여러 분야에서 활용되고 있으며, LDA 모델의 가정은 문서가 토픽들로 구성된 집합이고 토픽의 속성은 단어로 표현된다는 점이다. 이전의 방식은 연구자가 주제를 먼저 설정하고 각 문서를 주제별로 분류하는 것에 비해, LDA 토픽 모델링은 텍스트 데이터인 문서들의 숨겨진 토픽을 찾는 방식이라 토픽이 데이터에 의해 결정된다. LDA 토픽 모델링을 통해 여러 문서에 내포된 토픽을 추출할 수 있다. 따라서 LDA 토픽 모델링은 연구자 중심 주제 분류보다 더 객관적인 분석 방법이라 할 수 있다(박은희, 2021, p. 173-174).
토픽 모델의 범주는 대수학, 퍼지, 확률, 신경망 등으로 분류할 수 있다(Abdelrazek et al., 2023). 대수학의 원리를 적용한 토픽 모델의 대표적인 알고리듬은 Latent Semantic Analysis[LSA], Non-negative Matrix Factorization[NMF] 등이다. LSA7),는 TM에 아이디어를 제공하였고, NMF는 음수를 포함하지 않는 행렬곱을 분해하는 방식이다. 퍼지 모델은 문서에서 토픽을 추출한 후 부울 논리를 사용하여 토픽에 단어를 할당하는 방식이며, 예를 들어 트윗 등 짧은 텍스트 문서의 희소성 처리에 유리하다. 확률을 이용한 모델의 대표적인 알고리듬은 Latent Dirichlet Allocation [LDA]이다. NLP의 맥락에서 LDA는 토픽 모형을 산출하며, 단어 빈도들이 디리클레(Dirichlet) 분포를 따른다고 가정한다. 한 토픽이 한 문서의 실제 의미에 해당할 확률과 한 단어가 한 토픽에 속할 확률이 사전 확률분포를 따른다고 가정한다(류광, 2020, p. 162).
이 논문에서는 LSI와 LDA 알고리듬을 이용하여 토픽 수 결정의 과정에서 일관성 점수를 산출하여 비교하였으며, 복잡도(perplexis) 그래프도 함께 참고하였다. LDA는 토픽 모델링에서도 주로 사용되었으며, 토픽의 분포 및 토픽별 단어를 보여주는 시각화를 토픽 수 선정에 활용하였다. 이 과정에서 추출된 토픽별 단어들을 이용하여 교양교육의 지향성과 관련된 단어들을 정리해 보았다.
4. 결과 및 논의
4.1. 유럽 3개 University College의 Liberal Arts&Science
네덜란드의 EUC와 MUC 및 독일의 FUC LAS에서 제공하는 3개 문서를 통합한 435쪽의 데이터에서 단어를 추출하였다. 토큰화 및 불용어 처리 등 전처리를 거친 후 58,519개의 단어를 대상으로 빈도 분석 및 네트워크 구조 분석을 수행하였다. 유럽의 LAS 운영에서 빈도가 높은 단어를 알아보기 위해 빈도를 분석한 결과는 [그림 1]과 같다.
![[그림 1]](/upload//thumbnails/kjge-2023-17-4-11-gf1.jpg)
텍스트에서 빈도가 높은 단어 : 100개 및 15개
[그림 1]에서 왼쪽 그림은 파이썬으로 분석하여 빈도가 높은 100개 단어를 시각화한 결과이다. 오른쪽 그림은 15개 최빈 단어를 오렌지로 시각화한 것이다. 통합 문서에 출현한 각 단어의 빈도를 기준으로 실행된 왼쪽 그림에서 빈도 높은 단어가 크기를 통해 표시된다.8), 왼쪽 그림에서 ‘social, coordinator, research, topic, knowledge 등의 단어가 크게 표시되어 있어서 통합 데이터에서 빈도가 높은 단어로 볼 수 있다. 주요 단어를 알아보기 위해 오른쪽 그림에서는 파이썬으로 빈도를 계산한 상위 15개 단어를 제시하였다. 이 단어들의 빈도에 의한 순위는 research, social, international, coordinator, science, project, knowledge, skills, group, global, academic, human, theory, open, analysis이다.9) 유럽 UC의 LAS 프로그램에서는 교양교육에서 학술성(research, science, knowledge, academic, theory, analysis 등)을 지향하는 것으로 수 있다. 시대성(international, skills, global, open)으로 볼 수 있는 단어도 눈에 띈다. 보편성에 해당하는 단어로 social, human 등을 들 수 있으며, 운영과 연관되는 것으로 볼 수 있는 coordinator, project, group 등도 빈도가 높은 편이다.
유럽 3개 UC에서 제공하는 LAS 운영에 관한 텍스트 데이터에서 추출한 단어들의 빈도를 계산하여 나온 결과를 토대로 주요 단어 15의 네트워크를 구성해 볼 수 있다. 이를 통해 핵심 주제어들 사이의 연결 관계를 알아볼 수 있다. 이와 함께 네트워크에 있는 노드 사이의 조밀도(density)와 링크들의 연결도(degree)를 계산할 수 있다. 먼저 통합 문서의 15개 주요 단어를 이용한 네트워크의 구조를 [그림 2]에서 제시한다.
![[그림 2]](/upload//thumbnails/kjge-2023-17-4-11-gf2.jpg)
텍스트에서 추출된 15개 단어의 연결망 구조
[그림 2]의 왼쪽 연결망에서 5개 단어를 제외하고 나머지 10개는 분홍색으로 표시된 위치에 중첩되어 몰려있다. 단어들 사이의 연결을 보기 위한 오른쪽 연결망에서 5개 단어들에 연결선이 없는 것을 볼 수 있다. 다른 10개 단어는 대부분 서로 연결되어 있다. 이 네트워크의 전체 조밀도10),는 0.43이다. 조밀도가 1인 경우는 매우 드물고(손승우 외, 2022, p. 45), 이 연결망에서는 연결된 노드 쌍의 비율이 43% 정도라는 것을 알 수 있다.
이 네트워크의 연결도는 5개 단어에서 0이고 10개 단어에서는 9이다. 연결도란 노드의 연결선 수로서 링크 또는 이웃 노드의 수를 의미한다. 예를 들어 이웃이 없는 노드는 연결선 수가 없어서 연결도가 0.0으로 계산된다. 네트워크의 평균 연결선 수는 중요한 특성이고 조밀도와 비례한다. 네트워크에서 각 노드의 연결선 수는 네트워크의 구조에서 매우 중요한 속성이다(손승우 외, 2022, p. 48). 이 네트워크에서 5개 단어의 연결도는 0.0으로 이 단어들과 연결되는 다른 노드가 없다. 나머지 10개의 단어들은 연결도가 9인데, 이는 10-1로 각 단어들이 모두 서로 연결되어 있음을 의미한다.
유럽 UC의 LAS 문서에서 빈도가 높은 단어들을 더 보기 위해 빈도 기준 상위 30개 단어를 <표 4>에 정리하였다.

텍스트에서 빈도가 높은 30개 단어 및 출현 횟수
빈도 기준 상위 30개 단어를 기준으로 유럽 UC의 LAS 프로그램이 지향하는 바를 추정해 볼 수 있다. 예를 들어 research, science, knowledge, academic, theory, analysis, methods 등은 고등교육에서 학생들이 기본적으로 습득해야 하는 학문 탐구와 관련된 표현이다. 교양교육의 중요한 지향성인 학술성을 지향하는 것으로 볼 수 있다. [그림 2]의 네트워크 구조에서 위의 단어와 중복되는 단어인 research, science, knowledge, academic, theory, analysis는 다른 단어와 다르게 서로 긴밀하게 연결되어 있음을 보았다.
다른 예로 social, human, public, relations, development, questions, issues 등은 교양교육의 다른 지향성인 보편성과 연관된 단어로 볼 수 있다. 이러한 개념들은 누구에게나 보편적으로 적용될 수 있기 때문이다. 시대성과 관련된 단어로 international, global, open, contemporary, business, data, exchange, economic 등을 들 수 있다. 현재의 글로벌 열린 사회에서 교류하면서 데이터를 활용한 경제 활동을 하게 될 학생들에게 중요한 이슈이기 때문이다. 남은 단어 중에서 coordinator, project, free, tutorial, meetings 등도 주목할만하다. 실제로 교양교육을 운영할 때 중요하게 여기는 방법으로 볼 수 있으며, 프로젝트 중심 수업 및 선택의 자유와 더불어 담당 교수와의 지속적인 면담과 개별 지도를 통한 자기 주도적 학습의 지원이 중요하기 때문이다.
물론 전체 문서에서 단어가 출현한 빈도만으로 많은 정보를 얻기는 쉽지 않다(손복은, 전대일, 2020, p. 101). 빈도 분석의 결과로 추출한 주요 핵심어를 통해 유럽 UL의 LAS 프로그램의 특징을 간접적으로 조망할 수 있다. 특히 교양교육이 지향해야 할 특성을 보여주는 핵심어를 분류할 수 있다. 각 학문 분야의 기초교육을 중시하는 한국의 교양교육 실정과 달리 유럽 UC의 LAS는 보편성, 학술성, 시대성을 지향하는 것으로 이해할 수 있다. 이와 더불어 교양교육 운영 과정에서 염두에 두어야 할 사항에 대해 핵심어를 통해 부분적으로 관찰할 수 있다. 다양한 분야의 지식과 스킬을 종합적으로 습득하여 사회를 긍정적으로 변화시키는 데 공헌할 수 있는 인재로 성장하는 것을 지원하는 것이 유럽 UC의 LAS 프로그램의 핵심이다.
4.2. Amsterdam University College의 Liberal Arts&Science
원래 전체 교과목은 326개였으나 영역 사이의 중복, 외국어, 인턴십, 캡스톤 관련 교과목은 제외하였다. 토픽 모델링에 필요한 데이터 구조인 데이터 프레임을 만들기 위해 csv 형식의 데이터로 변환하였고 정규화, 토큰화, 불용어 처리 등 전처리를 거친 후 14,408개의 단어를 분석의 대상으로 삼았다.11)
비교를 위해 파이선과 오렌지를 이용한 시각화 결과를 [그림 3]에 제시한다.
![[그림 3]](/upload//thumbnails/kjge-2023-17-4-11-gf3.jpg)
텍스트에서 빈도 높은 단어 100개 및 15개
왼쪽의 그림은 파이썬으로 계산하여 얻은 단어의 빈도에서 상위 100개 단어를 대상으로 시각화한 것이고, 오른쪽 그림은 빈도 분석을 통해 상위 15개 단어를 오렌지로 시각화한 결과이다. 전체 문서에서 출현한 각 단어의 빈도가 높은 단어가 크기를 달리하여 표시된다. 왼쪽 그림에서는 ‘social, human, science, research, global, analysis, perspective, development, economic 등이 크게 표시되어 있어서 AUC LAS의 데이터에서 빈도가 높다고 볼 수 있다.12), 오른쪽 그림에서는 상위 15개 단어를 표시하였데, social을 중심으로 왼쪽에서 두드러지게 나타난 단어들을 구체적으로 볼 수 있다.13)
AUC LAS의 주요 단어 15를 대상으로 네트워크를 구성하여 [그림 4]로 제시한다. 왼쪽 그림에서 6개 단어를 제외하고 나머지 9개는 분홍색으로 표시된 위치에 중첩되어 몰려있다. 단어들 사이의 연결을 보기 위한 오른쪽 그림에서 6개의 단어들에 연결선이 없는 것을 볼 수 있다. 다른 9개 단어는 대부분 서로 연결되어 있다. 이 네트워크의 전체 조밀도는 0.34이다. 이 네트워크에서 연결된 노드 쌍의 비율은 34%이다. 이 네트워크의 연결도는 6개 단어에서 0.0으로 이 단어들에 연결되는 다른 노드가 없다. 9개 단어의 연결도는 8((-1)이고 각 단어들이 모두 서로 연결되어 있다. 이를 통해 social, international, global, media, various, economic 등 6개의 단어가 빈도는 높으나 이 네트워크에서는 의미적 연관성이 적다는 것을 알 수 있다. 연결도가 높은 9개의 단어들은 학술성과 보편성에 관련되고 나머지 6개는 시대성과 관련이 있는 것으로 볼 수 있다.
![[그림 4]](/upload//thumbnails/kjge-2023-17-4-11-gf4.jpg)
텍스트에서 추출된 15개 단어의 구조
AUC의 LAS 문서에서 빈도가 높은 단어들을 더 보기 위해 빈도 기준 상위 30개 단어를 <표 5>에 정리하였다.

빈도가 높은 30개 단어 및 출현 횟수
빈도 기준의 상위 30개 단어를 통해 AUC에서 제공하는 LAS의 지향점을 추정해 볼 수 있다. 예를 들어 social, human, development, public, culture, body, order 등의 단어는 교양교육의 보편성과 관련된다고 볼 수 있다. 다른 예로 science, research, analysis, knowledge, perspective, theme, writing, scientific, attention 등의 단어는 교양교육의 학술성이라는 지향성과 연결할 수 있다. 이와 더불어 international, global, data, media, various, economic, contemporary, energy 등은 교양교육의 시대성과 관련이 있다. 다른 단어 discuss, role, body, practice 등은 교수-학습과 관련이 있는 것으로 볼 수 있다.
단어의 빈도만으로 문서의 내용을 모두 파악하기는 쉽지 않다. 어떤 단어는 대부분의 문서에서 등장하는 경우가 많아서 이를 통해 통찰을 얻기에는 부족하기 때문이다. 예를 들어 [그림 4]에서 연결도 0인 단어들은 빈도가 높으면서도 연결된 노드가 없는데, 이러한 단어들은 여러 문서에서 출현할 확률이 높다. 이를 확인하기 위해 tf-idf 계산을 적용하는 토픽 모델링 기법을 활용한다. 이를 통해 유럽 3개 UC와 AUC UC의 LAS에서 제공하는 내용을 더 알아볼 수 있기 때문이다.
토픽 수 결정을 위한 지표에는 일관성 점수와 복잡도가 있다. 일관성 점수는 LSA14), 및 LDA 알고리듬을 통해 얻을 수 있다. 이다. 이를 위해 문장을 구성하는 단어들을 벡터로 변환하여 각 문서에서 특정 단어가 출현한 빈도를 문서 수에 해당하는 차원의 공간에서 표시한다.15) 차원 축소나 토픽 모델링을 통해 원래의 차원에서는 볼 수 없는 단어들을 같은 차원에서 관찰하면서 단어들 사이에 높은 상관성이 있음을 알 수 있다. 축소된 각 차원은 문서 내에 존재하는 하나의 토픽이며, 이 토픽에 포함된 단어들을 이용하여 토픽을 추론할 수 있다. LSA는 유사도가 높은 단어를 같은 토픽으로 분류하며, 한 토픽에 포함된 단어들을 보고 추상적인 토픽을 추론하여 토픽의 제목을 정할 수 있다.
LDA는 방대한 텍스트 자료로부터 토픽을 추출하는 확률 기반의 알고리즘이며, 복수의 문서에서 토픽을 잠재적으로 가정하여 문서들의 토픽을 확인할 수 있다. 문서들에서 토픽들의 확률분포 θ와 각 토픽을 구성하는 단어들의 확률분포 z가 주어졌을 때, 문서를 구성하는 토픽을 확률적으로 선택하고 선택된 토픽에 포함된 단어를 확률적으로 선택하는 샘플링 과정을 반복하여 문서들에서 주요 토픽을 생성하는 모델이다(Blei et al., 2003). LSA와 LDA에서는 토픽 수에 따라 점수가 높은 경우에 적절한 토픽 수로 여긴다. 복잡도(perplexity)는 확률 모델의 비교에 사용되는 측도이며, 복잡도가 낮을수록 성능이 좋은 것으로 해석된다(위키피디아).
지면을 절약하기 위해 상세한 설명은 생략하고 AUC LAS의 텍스트 데이터를 이용하여 각각 실행한 결과는 [그림 5]와 같다. [그림 5]의 왼쪽 그래프는 LSA의 결과이며, 적절한 토픽 수는 15 > 16> 12 순으로 나왔다. 가운데 그래프에서는 LDA의 결과가 15 > 12 > 17 순으로 적절한 토픽 수라는 것을 보여준다. 오른쪽 그래프에서 복잡도 점수는 토픽 수 16일 때 점수도 낮은 편이고 감소도 완만하다. LSI 및 LDA 모델의 일관성 점수, 복잡도 점수를 고려하여 15개, 16개, 12개를 토픽 수의 후보로 하여 LDA 모델로 토픽 모델링을 수행하였다. LDA 모델은 pyLDAvis라는 시각화 도구를 제공하고 있어서 분석에 유용한 정보를 제공하기 때문이다. 문서의 규모에 비해 토픽 수가 많은 편이라서 8개를 포함하여 실행한 결과를 비교하기 위해 [그림 6]과 같이 제시한다.
![[그림 5]](/upload//thumbnails/kjge-2023-17-4-11-gf5.jpg)
토픽 수 결정을 위한 LSA, LDA, Perplexity 실행 결과
![[그림 6]](/upload//thumbnails/kjge-2023-17-4-11-gf6.jpg)
토픽 수 결정을 위한 결과 비교 : 15개, 16개, 12개, 8개
[그림 6]에서 왼쪽의 위는 15개, 아래는 16개, 오른쪽의 위는 12개, 아래는 8개의 토픽 수에 따른 토픽의 분포를 2차원상에 그려서 토픽들의 관계를 표현하고 있으며, 위치가 근접한 토픽들은 유사도가 높다. 다른 그림에 비해 토픽 수가 8인 경우에 토픽들이 고른 분포를 보이고, 다른 그림에서는 1번 원에 비해 작은 원이 있으나 대체로 균등한 크기의 원으로 구성되어 있다. 다른 그림과 달리 토픽 사이의 중복이 없고 거리도 떨어져 있는 편이다. 이에 따라 8개를 토픽 수로 지정하여 토픽 모델링을 수행하였다.
토픽 모델링 이후에 각 토픽의 단어들이 차지하는 비율을 볼 수 있고, 토픽별 단어 분포를 알 수 있으며, 이를 [그림 7]에 제시한다.
![[그림 7]](/upload//thumbnails/kjge-2023-17-4-11-gf7.jpg)
토픽 수 8개의 토픽별 비율 및 단어 분포
[그림 7]의 왼쪽에 보이는 각 토픽의 분포에서 원의 크기는 토픽에 포함된 단어의 수와 관련이 있다. 오른쪽에는 토픽별 단어 30개와 각 단어의 빈도를 표시한다. 오른쪽 위에 각 토픽이 전체 단어에서 차지하는 비율이 표시되며, 예를 들어 토픽 1은 18.2%이다. 토픽 1에는 social 등이 할당되어 있고 그림에서는 상위 빈도의 30개 단어를 보여준다. 파란색은 해당 단어가 문서 전체에서 출현하는 빈도를 표시하고 빨간색은 해당 토픽에서 그 단어의 빈도를 표시한다. 왼쪽 그림에서는 토픽 사이의 거리도 표시한다.
이를 토대로 토픽별 단어 분포를 비교하기 위해 상위 5개씩의 단어를 <표 6>에 정리한다.

토픽별 비율 및 주제어 5개
<표 6>에서 볼 수 있듯이 예를 들어 social, human, science 등 단어의 경우 순위(빈도)는 다르지만 여러 토픽에서 등장하고 있다. 각 토픽에 속하는 단어들이 전체 단어에서 차지하는 비율은 8%~18.2%로 비교적 고르게 분포하고 있다.
의미연결망 분석을 위해 [그림 7]에서 보여주는 토픽별 단어를 활용하였다. 각 토픽별 상위 15개 단어를 사용하여 의미연결망 구조를 시각화하고 중심성을 계산할 수 있다. 토픽 내 주요 단어 간 네트워크를 볼 수 있기 때문이다(손복은, 전대일, 2020, p 97). 이를 위해 8개 토픽의 상위 15개 단어 목록을 <표 7>에 제시한다.
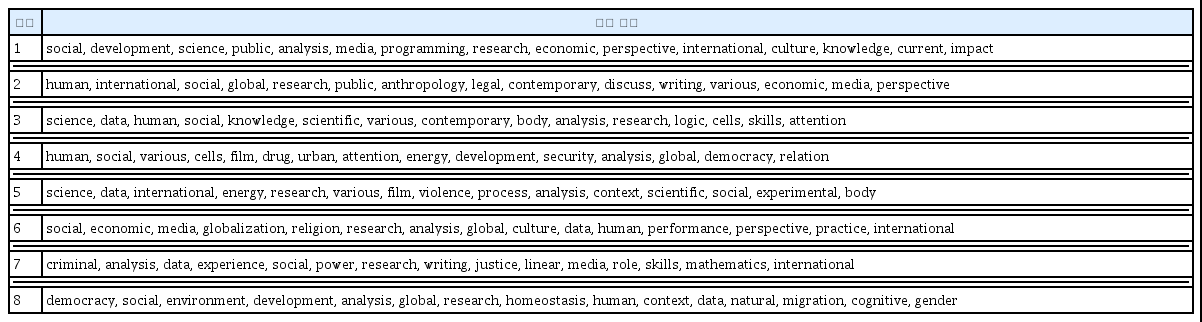
의미연결망 구조를 위한 8개 토픽별 상위 15개 단어 목록
시로 토픽 1의 15개 단어 및 횟수를 <표 8>에 제시한다.

토픽별 상위 15개 단어의 순위 및 횟수 예시
<표 8>에서 1번 토픽에 속하는 단어들의 순위는 해당 단어의 전체 빈도가 아니라 해당 토픽에서 그 단어의 중요성에 따라 매겨진다. 이에 따라 토픽 내 해당 단어의 중요도 순위와 출현 횟수의 순위는 일치하지 않는다. 토픽별 단어의 횟수를 중심으로 네트워크 구성 결과를 토픽 1의 경우를 예시로 제시하면 [그림 8]과 같다. [그림 8]에서 주제어 간 네트워크가 형성되고 있음을 확인할 수 있다(임수민 외, 2020, p. 21). 왼쪽 그림에서처럼 한 토픽에 속하는 모든 단어가 연결되는 것은 아니고 일부 단어는 연결되지 않은 것을 볼 수 있다.16) 시각화된 네트워크에서 점(node)은 주제어를 의미하며, 선(link)은 주제어 사이의 연결을 의미한다. 왼쪽 그림에서 분홍색 주변의 주제어들은 의미적으로 매우 긴밀하게 연결되어 있다. 나머지 4개의 주제어는 다른 주제어와 연결 관계가 더 느슨한 것을 보여주고 있으며, 이는 오른쪽 그림에서 보여주는 주제어간 연결선을 통해서도 확인할 수 있다. 토픽 1을 구성하는 단어들 사이에서도 의미적 연결의 정도가 다른 것을 보여주는 사례이며, 의미적 연결이 비교적 덜 긴밀한 단어들은 시대성을 반영하는 것으로 볼 수 있다.
![[그림 8]](/upload//thumbnails/kjge-2023-17-4-11-gf8.jpg)
토픽별 상위 15개 단어로 만든 네트워크 구조 예시
4.3. 한국 교양교육 개선에 접목 가능성
4.3.1. 교양교육의 지향성 차원
앞서 글로벌 시대 기술 발전 사회에서 교양교육이 지향해야 할 중요한 특성으로 보편성, 학술성, 시대성을 언급하였다. 보편성에는 인간, 사회, 자연 등이 포함될 수 있다. 학술성은 고등교육의 고유한 역할인 연구 수행에 필수인 과학적 방법, 분석적 사고 등과 관련이 있다. 시대성은 고전과 더불어 기술 발전에 따른 글로벌화를 반영하는 것을 말하며, 새로운 지식과 기술은 물론이고 융복합 성격의 교과목이나 응용과학까지 포함할 수 있다. 이러한 교양교육의 지향성 차원에서 유럽 UC의 LAS 프로그램의 한국 상황에 접목할 가능성을 논의하기 위해 앞에서 각각 제시한 유럽 3개 UC의 LAS와 AUC LAS의 텍스트 분석 결과를 비교한다.
비교를 위해 빈도 높은 15개 단어를 시각화한 그림을 [그림 9]에서 함께 제시한다.
![[그림 9]](/upload//thumbnails/kjge-2023-17-4-11-gf9.jpg)
유럽 3개 UC와 AUS LAS의 상위 15개 단어 비교
왼쪽 유럽 3개 UC LAS 텍스트 분석의 결과에서 빈도가 가장 높은 research를 중심, 오른쪽 AUC LAS 텍스트 분석의 결과에서 최빈 단어인 social을 중심으로 표현되고 있다. 앞에서 분류한 바에 따르면 전자는 학술성을, 후자는 보편성을 강조하는 것으로 볼 수 있다.
<표 9>에서는 두 텍스트 분석의 결과로 추출된 상위 15개의 순위를 함께 보여준다.
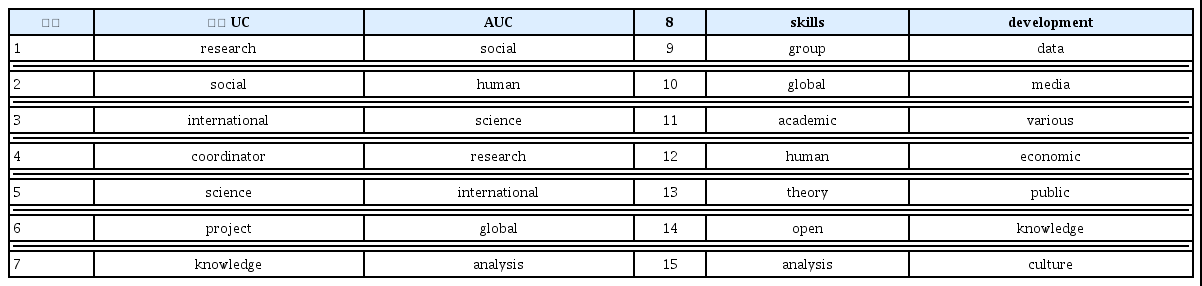
유럽 3개 UC와 AUS LAS의 상위 15개 단어 순위 비교
두 데이터에서 공통으로 출현하는 단어는 research, social, international, science, knowledge, global, human, analysis 등 8개이다. 보편성 관련 단어로 social과 human을, 시대성 관련 단어로 international과 global을 들 수 있다. 학술성 관련 단어에는 research, science, knowledge, analysis 등이 포함될 수 있다. 유럽 데이터에서 상위 빈도인 단어는 coordinator, project, skills, group, academic, theory, open 7개이고, AUC 데이터에서는 development, data, media, varioius, economic, public, culture 등 7개 단어가 상위 빈도에 속한다. 전자는 운영이나 교수-학습에 관한 단어가 많은 편이고, 후자는 시대성을 표현하는 단어들을 포함하고 있다. 두 데이터의 상위 15개 단어를 지향성 차원에서 분류할 수 있다.
더 많은 최빈 단어를 이용한 상세 비교를 위해 두 텍스트 데이터의 분석 결과로 추출된 빈도 상위 30개 단어의 순위와 횟수를 앞서 제시한 <표 4>와 <표 5>를 통합하여 <표 10>으로 함께 제시한다. 공통되는 단어와 각 텍스트에서 추출된 서로 다른 단어들을 중심으로 지향성 차원에서 논의할 수 있기 때문이다.
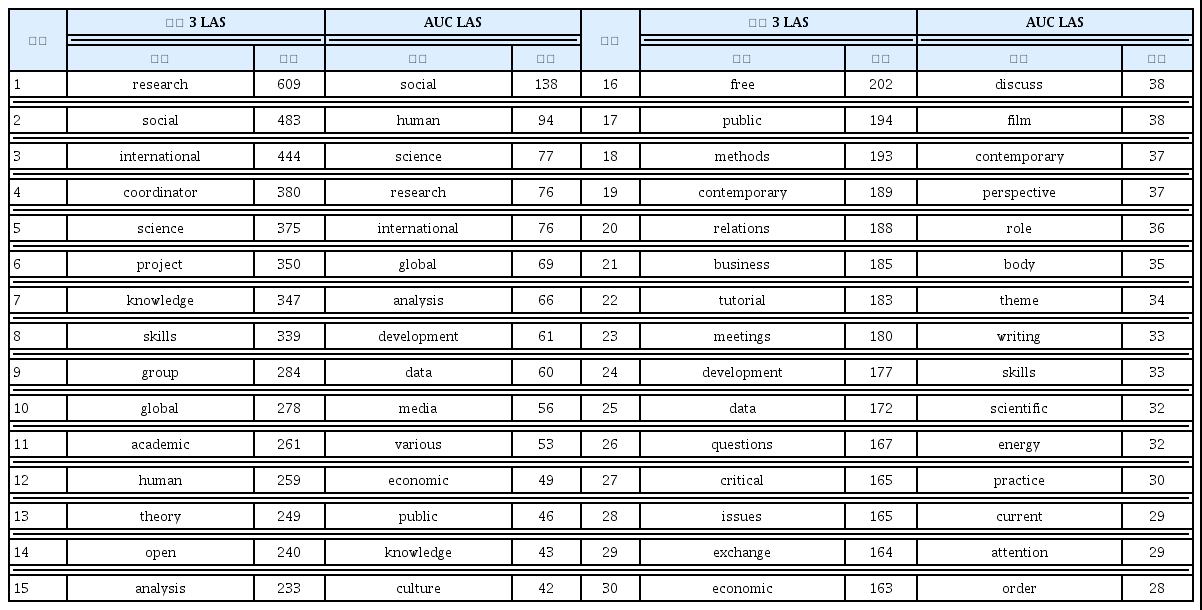
유럽 3개 UC와 AUC LAS 텍스트에서 추출한 30개 최빈 단어 비교
두 데이터에서 동시에 출현하는 최빈 단어는 research, social, international, science, knowledge, skills, global, human, analysis, public, contemporary, development, data, economic 등 14개이다. 이를 교양교육의 지향성에 따라 분류하자면 보편성에는 social, human, public, development 등의 단어가 포함될 수 있다. 학술성과 관련된 단어는 research, science, knowledge, skills, analysis 등이다. 시대성을 표현하는 단어로 international, global, contemporary, data, economic 등을 언급할 수 있다.
총 30개의 단어에서 차이를 보여주는 단어는 16개이지만, 예를 들어 project와 practice, group과 relations, academic와 scientific, critical과 discuss, issues와 theme 등은 유사한 의미를 표현한다고 볼 수 있다. 특히 상위 30개 단어에는 교양교육의 지향성과 더불어 중요한 요소라 할 수 있는 운영과 교수-학습 관련 표현으로 분류할 수 있는 단어들도 있다. 예를 들어 유럽 UC 데이터에서 coordinator, project, free, tutorial, meetings, exchange 등은 LAS 운영과 연관이 있다. AUC 데이터에서 discuss, role, body, practice, attention 등은 교수-학습에 관한 것이다.
유럽 LAS 프로그램에서는 학생을 교육 혁신의 잠재적 근원으로 여긴다는 점에서 대부분 여전히 공급자 중심인 한국의 고등교육 시스템에 시사하는 바가 크다. 특히 ECOLAS 선언문에서 강조하는 ‘고등교육이 지식 전달만 하는 것이 아니라 사회의 요구에 대응하는 데 필요한 스킬 습득의 기회 제공’, ‘좁은 과목 학습이 아니라 능력 실현을 위한 학생 중심 학습’, ‘학생 자신의 관심’, ‘다양한 관점에서 문제 해결하기 위해 이론을 적용할 기회 제공’, ‘산업 분야의 과업을 수행하는 데 필요한 지적 소프트 스킬 습득 지원’, ‘사회 전체의 유지 및 발전에 필요한 스킬과 태도 배양의 기회 제공’ 등 LAS의 목표를 주목해야 한다(ECOLAS Manifest, 2021).
4.3.2. 교양 교육과정 운영 차원
유럽 UC의 LAS 프로그램이 시대와 사회의 요구를 반영하는 교육을 강조한다는 측면에서 한국의 학과 중심 교양교육 운영에 대해 재고할 것을 시사한다. 한국의 대학에서도 원론적이고 이상적으로는 ECOLAS의 목표와 유사한 내용을 슬로건으로 내세우는 경우가 많지만, 이를 구체적으로 실현할 교육과정 운영에서는 학과나 전공의 영향을 받는 경우도 적지 않기 때문이다. 이를 위해 전담교수제 도입을 생각해볼 수 있다. 유럽의 LAS 텍스트에서 coordinator라는 단어가 자주 언급된 것을 보았다. 교수와 학생으로 구성된 커뮤니티를 형성하여 전문적이고 밀도 높게 지도하기 위해서는 전문성을 갖춘 교수진이 교양교육의 운영 주체가 되어야 한다. 유럽 UC 데이터에서 자주 등장한 coordinator, project, free, tutorial, meetings, 등을 실천할 수 있는 전담교수가 필요하기 때문이다.
교육과정 편성에서도 한국식 분과 학문의 기초 교과목 중심의 관행을 탈피하여 교양교육의 지향성을 연계한 교과목으로 편성할 필요가 있다. 교양교육의 지향성을 구성원 다수의 합의로 도출한 것을 전제로, 세부 지향성을 중심으로 교과목을 편성할 때 유럽 UC의 LAS 텍스트 분석 결과로 나온 토픽이나 중심어를 참고할 수 있을 것이다. 앞서 알아보았듯이 유럽의 LAS 프로그램에서는 이러한 방향의 교과과정을 이미 편성하고 있기 때문이다. 이와 더불어 유럽 LAS 모델을 한국 대학의 교양교육 개선에 적용하는 문제를 논의하기 위해 AUC에서 제공하는 ‘Academic Standards and Procedures 2022- 2023[ASP]’17),이라는 자료의 내용을 활용할 수 있다(Amsterdam University College, 2022).
ASP의 내용을 일별하기 위해 텍스트 데이터를 전처리한 후 코딩을 거쳐 워드 클라우드와 네트워크 구조로 시각화하면 [그림 10]과 같다.
![[그림 10]](/upload//thumbnails/kjge-2023-17-4-11-gf10.jpg)
ASP 텍스트 대상 빈도 분석 및 시각화 결과
왼쪽 그림에서 theme, social, academic, research, skills 등의 단어가 크게 표현되고 있으며, 앞의 분석 결과에서 추출된 주제어와 유사하다.
운영이나 이수에 관한 텍스트라서 시대성을 표현하는 단어는 많지 않아도, 학술성 관련 단어가 많고 보편성 관련 단어도 보인다. 가운데 그림과 오른쪽 그림의 연결망에서도 학술성 관련 단어들의 연결도가 높은 것을 볼 수 있으며, 학술 활동에서 중요한 표절도 중요한 것으로 표현되어 있다. 무엇보다도 theme이라는 단어가 크게 표시되고 연결도 많은 것을 통해 주제 중심 교육과정 편성을 읽을 수 있다.
실제 교과목의 특징을 살펴보기 위해 앞에서 분석 대상으로 삼은 AUC LAS의 226개의 교과목명을 데이터로 하여 시각화하면 [그림 11]과 같이 제시할 수 있다.
![[그림 11]](/upload//thumbnails/kjge-2023-17-4-11-gf11.jpg)
AUC LAS에 편성된 226개 교과목 명칭에 포함된 단어
왼쪽과 가운데 그림은 226개 교과목 전체를 대상으로 시각화한 것이고, 오른쪽은 5회 이상 출현한 중심어를 시각화한 그림이다.18)
가운데 그림에서 Introduction, Theme, Lab 등의 단어가 크고 양쪽 그림에서도 중심부에 있는 것으로 볼 때 주제를 강조하고 있는 것을 알 수 있다. 교과목명에서 Introduction이라는 단어가 많이 포함되어 있음을 짐작할 수 있다. 중심어 Modern, Global, Economic, World, Economics, Environmental 등의 단어를 통해 시대성을 반영하는 것으로 생각할 수 있다. 앞의 분석에서 빈도가 높았던 research나 social 등이 보이지 않은 것은 실제 교과목 명칭에서는 이러한 표현을 많이 사용하지 않으나 교과목을 설명할 때는 자주 언급하기 때문일 것이다.
더 상세한 특징을 살펴보기 위해 교과목명 데이터를 문서로 하여 8개 토픽으로 모델링하여 얻은 토픽별 주제어를 정리하면 <표 11>과 같다.

AUC LAS의 교과목명 대상 토픽 모델링 결과 (비율 단위 : %)
226개의 교과목명 데이터로 토픽 수 8개로 모델링하여 토픽별로 상위 5개 단어를 추출한 결과로 Theme이라는 주제어가 8개 중 5개 토픽에서 나타나고 순위도 상위권이다. 주제어Introduction도 절반의 토픽에 포함되어 있고 순위도 대체로 높은 편이다.
교과목의 명칭에서 이미 주제 중심으로 접근하고 있다. 교과목명에 Introduction이 많이 포함된 것은 교양교육의 특성상 당연한 것으로 볼 수도 있다. 그러나 이 주제어가 포함된 총 18과목 중 11개 과목이 독립적인 과목인데,19), 대체로 기초과학의 기본 과목 및 문화학, 공공보건, 시각 방법론 등 융복합 성격의 학제적 주제에 대한 입문 과목이다. 나머지 7개 과목도 Theme을 전제로 하는 과목들이다.20) 주제어 Theme이 포함된 과목은 17개 과목이며, Introduction 7과목 외에 10개 과목이 이에 해당한다.
특히 Big이라는 주제어가 포함된 과목이 5개로 빈도는 아주 높은 편이 아니지만,21) 한국 대학의 인문학 분야 교양 교과목 개설에 시사하는 바가 있다고 본다. 인문학의 하위 분과학문이 편제된 많은 대학에서 지나치게 세분화된 과목을 개설하다 보니 큰 안목으로 현상이나 세상을 바라볼 기회를 차단할 위험이 있기 때문이다. 특히 이른바 영역별 배분 이수제를 시행하는 경우 특정 영역에서 세분화된 일부 내용만 학습하다 보면 시야가 좁아질 우려도 있다. 한국 대학의 교양교육에서 중요한 비중을 차지하는 경우 글쓰기 기초만 다루는 경우가 많은데, 연구를 위한 상급 글쓰기 과목을 개설할 수 있다. 결과적으로 기초학문의 세부 학과나 전공의 기초 과목이 아니라 토픽과 주제 중심으로 교과목을 편성하는 것이 바람직하다.
AUC LAS 프로그램에서 주목할 과목으로 캡스톤(Capstone)을 들 수 있다. 이 과목은 정규 교육과정에 편성되어 있다(ASP, 2022, p. 10). 캡스톤 과목은 습득한 지식의 종합적 적용 기회를 제공하기 위해 한국의 교양교육에서 도입하는 것을 검토할 필요가 있다. 한국의 교양교육에서도 종합적인 지식 활용을 경험할 수 있는 캡스톤 프로젝트를 정규 교과목으로 편성하여 고학년 학생들에게 기회를 제공해야 한다. 특히 자유전공학부의 경우 이러한 교과목을 통해 자율적으로 설계한 전공을 이수하는 과정에서 배운 지식과 스킬을 적용하는 단계가 필요하다. 이 과정에서 캡스톤 프로젝트를 담당하는 교수의 역할이 중요하다. 특히 비교적 소규모로 운영되는 자유전공학부에서는 자기 설계로 구성된 교과과정을 이수하는 과정에서 습득한 지식과 스킬을 종합적으로 적용하기 위해 이러한 성격의 과목이 필요하다.
5. 결론
한국 대학에서 교양교육의 지향점을 반영한 개선의 어려움이라는 문제의식을 토대로 이러한 문제 해결을 위해 유럽의 일부 UC에서 제공하는 LAS 프로그램 분석의 필요성에서 출발하였다. 유럽에서 LAS는 보편성, 학술성, 시대성이라는 현대 교양교육의 지향점을 반영하고 있어서 분과학문의 영향을 많이 받는 한국 교양 교육과정의 한계를 보완해 줄 수 있기 때문이다. 이를 위해 먼저, 유럽 UC의 LAS와 방법론 관련 이론을 간단히 정리하고 선행연구를 검토하였다. 이를 통해 유럽 UC의 LAS 텍스트에서 빈도가 높은 핵심어, AUC LAS 교과 요목의 토픽 및 주제어, 한국 교양교육 개선에 시사점 등 연구 문제를 도출하였다. 이 논문에서는 교양교육이 지향할 특성으로 보편성, 학술성, 시대성으로 설정하고 이를 토대로 유럽의 LAS 관련 텍스트에서 시사점을 찾고자 하였다.
이어서, 유럽의 3개 UC 및 AUC의 교과 요목, 이수 규정 등에 관한 텍스트를 수집하여 전처리한 후에 빈도 분석, 토픽 모델링, 의미연결망 등의 기법을 이용하여 데이터를 분석하였다. 두 데이터의 빈도 분석 결과를 기반으로 14개의 공동 중심어를 추출하여 보편성 4개(social, human, public, development), 학술성 5개(research, science, knowledge, skills, analysis), 시대성 5개(international, global, contemporary, data, economic) 등으로 분류했다. AUC의 교과목명을 데이터로 사용하여 8개 토픽별 5개의 주제어를 분석한 결과 226개 과목 중 Introduction이 포함된 과목이 18개였다. 융복합 성격의 교과목에 대한 입문 과목이 11개이고 주제 중심 과목이 7개로서, 세부 분과학문의 입문 과목 중심으로 구성된 한국 교양교육의 개선에 고려할 사항이다.
마지막으로, 분석 결과를 바탕으로 한국 대학의 교양교육 개선에 주는 유럽의 시사점을 정리하였다. 두 데이터의 빈도 분석, 토픽 모델링, 의미연결망 구조 등의 과정에서 유럽 UC와 AUC의 LAS 프로그램이 이 논문에서 설정한 보편성, 학술성, 시대성을 비교적 두루 반영하고 있는 것을 확인하였다. 한국교양기초교육원에서 제공하는 2022 한국 교양교육 표준모델의 내용을 일부 뒷받침하는 것으로 볼 수 있다. 유럽 UC와 AUC의 LAS 프로그램에서 제공하는 정보를 이용하여 교양교육의 운영에 관해 전담 교수제 도입, 융복합 교과목 편성, 자기 설계 과정에서 지도교수의 역할 강화, 교수-학습법 개발 등을 중심으로 제언하였다. 일부 대학에서는 이러한 사항을 운영에 반영하기도 하나 다시 강조해도 지나치지 않은 내용들이다.
이 논문의 한계는 유럽의 모든 LAS 프로그램 관련 텍스트 데이터를 분석하지 못한 점이다. 방법론의 측면에서도 컴퓨터가 코딩을 통해 산출한 결과를 신뢰할 수 있는가의 문제가 지적될 수 있다. 그러나 이전의 문헌 중심의 연구와 달리 새로운 기술을 이용한 연구의 가능성을 실현한다는 데 의의를 둘 수 있을 것이다. 텍스트 데이터 분석 기반의 이러한 논의는 한국 교양교육의 표준안 개선, 각 대학의 교양교육 개편, 자유전공학부의 교양교육 운영에 활용할 수 있을 것이다.
후속 연구에서 한국의 교양교육 관련 텍스트 데이터를 대상으로 분석해서 더 정밀하게 실상을 진단할 수 있다면, 시대와 사회가 요구하는 대학 교양교육의 개선 방향을 설정하는 데 유용할 것이다. 고등교육은 미래의 사회에서 요구하는 지식과 스킬을 학생들이 준비할 기회를 제공해야 한다. 대학생들은 무한한 잠재력을 지니고 있으므로 고등교육은 학생들이 자신의 잠재력을 개발할 수 있게 도움을 줄 수 있어야 한다. 전공교육보다는 교양교육에서 이러한 역할과 기능을 담당해야 한다. 모든 학생을 대상으로 연구 능력과 실용 기술을 두루 겸비한 인재 교육에 적합한 조건을 가지고 있기 때문이다. 대학이 학생들의 잠재력 개발을 위한 최적의 프로그램을 제공하지 못하면 학생들의 인생이 불행할 수도 있다는 점을 학부 교양교육의 개선 과정에서 염두에 두어야 한다.
References
Notes
Liberal Arts & Science의 번역어로 ‘교양학’을 쓸 수 있으나, 논란의 여지가 있어 LAS로 사용함.
확인을 위한 검색일(2023년 6월 11일) 현재 영국(9), 네덜란드(7), 리투아니아(3), 독일(2), 벨라루스(1), 슬로바키아(1), 슬로베니아(1), 이탈리아(1), 체크(1) 등.
네트워크(network)는 상호 연결된 개체인 노드(node)와 노드들 사이의 연결(link)로 구성됨.
분절된 단어들에 벡터값을 부여하고 차원 축소를 통해 근접한 단어들을 토픽으로 묶는 모형.
단어가 특정 토픽에 존재할 확률과 문서에 특정 토픽이 존재할 확률을 추정하여 토픽 추출.
신경망을 활용하는 BERTopic도 까다로운 사후 추론을 최적화로 대체할 수 있는 장점이 있으나, 기술 및 지면의 이유로 이 논문의 범위에는 포함하지 않고 후속 연구로 남김.
Latent Semantic Indexing의 약자로 LSI라는 용어로 사용하기도 함.
max_font_size는 80으로, relative_scaling은 .7로 지정. 글자색은 선택할 수 있고 위치는 무작위.
각 단어의 출현 횟수는 <표 4>에서 함께 제시함.
조밀도란 연결된 노드 쌍의 평균과 최대 연결선 수의 비율. 완전 네트워크는 최대 조밀도인 1로 계산되며, 가능한 모든 노드 쌍이 링크로 서로 연결되어 최대 링크 수를 갖는 네트워크에 해당함.
상세한 데이터 전처리 과정은 <표 3> 참조.
빈도 순위 : social, human, science, research, international, global, analysis, development, data, media, various, economic, public, knowledge, culture.
각 단어의 출현 횟수는 <표 5>에서 함께 제시함.
단어의 의미를 복수의 문서에서 동시에 출현하는 동시성(co-occurrence)을 통해 파악하는 방법.
예를 들어 특정 단어가 10개의 문서에 출현한 빈도가 0, 0, 0, 0, 2, 4, 5, 6, 7, 8회일 경우 해당 단어는 10차원의 공간에서 0, 0, 0, 0, 2, 4, 5, 6, 7, 8라는 벡터로 표현됨.
다른 토픽들에서도 유사한 결과가 나왔기 때문에 다른 토픽들의 네트워크 구조 그림은 생략함.
AUC의 LAS 프로그램 운영 및 교육과정 이수에 관한 정보를 제공하는 자료.
교과목의 원래 명칭을 함께 보기 위해 가운데 그림에서는 소문자화 전처리를 하지 않음.
Biology, Chemistry, Cultural Analysis, Environmental Sciences, Financial Mathematics, Geological Sciences, GIS, Literary and Cultural Theory, Physics: The Mechanical Universe, Public Health, Visual Methodologies.
Cities and Culture, ECS(지속 가능성, 기후 변화 등), HW(건강과 웰빙), ICC(인간과 인공지능 : 정보 구조, 기계학습, 인간-기계 상호작용, 집단 지성, 표현과 감정, 기억, 뇌의 구조, 신경 처리, 시각적 인식, 사회적 인지 등), LEU(통합과학: 진화, 시스템, 네트워크 등), Social Systems 1, Social Systems 2.
Big Questions in Science, Big Questions in Future Society, Big Data, Big Books: World Literature, Big History.