잠재디리클레할당(LDA)을 활용한 대학생의 동료평가 기준에 관한 탐색적 연구
An Explorative Research Towards the Criteria of Peer Evaluation Among University Students Using Latent Dirichlet Allocation (LDA)
Article information
Abstract
초록
이 연구는 팀 기반 학습이 일어나는 수업 현장에서 진행될 동료평가의 판단 기준을 탐색해보기 위해 수행되었다. 이를 위해 D 대학 57명 학생들을 대상으로 팀 활동 기반 동료평가 결과를 수집하였고, 잠재디리클레할당(Latent Dirichlet Allocation; LDA)를 활용하여 1차와 2차에 걸쳐 수집된 동료평가 결과를 분석하였다. 연구 결과, 학생들은 적극성을 가장 중요한 판단기준으로 삼았다. 특히, 좋았던 점과 관련된 동료평가의 경우 1차와 2차 모두 적극성이 중요한 역할을 하였고, 이는 2차 시기로 갈수록 더욱 중요해지는 양상을 보였다. 반면, 개선해야할 점의 경우, 1차 시기에서는 적극성이 강조되었으나, 2차 시기에서는 의사소통능력이 더 강조되었다. 이를 통해 교수자는 팀 활동 이전에 적극적인 태도를 보이는 것이 중요하다는 점을 강조하고, 팀 활동이 진행되면 의사소통능력을 향상시켜 나가는 것이 필수적이라는 메시지를 전달할 필요가 있다.
Trans Abstract
Abstract
The purpose of this study is to explore criteria of peer evaluation in team-based learning. Participants of the study are 57 students attending D university, and the students provided positive and negative feedback to their team members. The feedback was provided two times during the class. To analyze the feedback results, LDA (Latent Dirichlet Allocation) was used, and the results showed that in general the students seemed to consider positiveness as the most important criterion of peer-evaluation. In particular, the results regarding the positive feedback showed that positiveness was the most important criterion for both responses. Furthermore, the importance of positiveness seemed to become more important as the class progressed. However, the results regarding negative feedback showed that communication skill was going to become important as the class progressed. Thus, teachers need to emphasize positiveness in their team-based learning in the beginning of their classes, but they also need to deliver the message that the communication skill is the other important criterion as the class progresses.
1. 서론
최근 전세계적인 COVID-19의 확산으로 인하여, 대학은 한 학기 전체를 비대면 교육으로 운영해야 하는 미증유의 상황을 맞이하였다. 그리고 이를 해결하는 방안으로써, 온라인 교육과 오프라인 교육을 합친 블렌디드 러닝(blended learning)이 주목 받고 있다(Siripongdee, Pimdee, & Tuntiwongwanich, 2020). 블렌디드 러닝을 운영하는 교수자는 온라인 교육과 오프라인 교육이 이루어지는 주차를 사전에 정하며, 교과목 특성에 따라서 온라인 교육과 오프라인 교육의 비중이 다르다(Page et al., 2017). 현재 COVID-19의 상황을 보면, 다음 학기에도 블렌디드 러닝을 선택하여 온라인 교육과 오프라인 교육을 병행하는 대학이 많을 것이다(이보경, 2020). 이때, 온라인으로 학습한 내용을 실제 적용해 보는 오프라인 교육이 다수의 교양 교과목에서 팀 프로젝트 형태로 진행될 경우, 동료평가에 관한 관심은 급격히 높아질 것이다.
팀 기반 학습은 팀의 공동 목표를 달성하기 위해서, 팀원 간의 효율적인 의사소통 체계를 가지고 상호작용하는 구조화된 교수-학습 방법이다(Michaelson, Knight, & Fink, 2004). 팀 기반 학습에서는 무임승차 문제가 필연적으로 발생하는데(Michaelson & Sweet, 2008), 이를 해결하고 평가의 공정성을 확보하기 위한 방안으로 동료평가가 널리 활용되고 있다(정은숙, 2018). 동료평가에 관한 선행연구는 동료평가의 효과성에 초점을 맞춰, 학생들의 전문성, 자기 조절 능력, 팀 기반 학습의 만족도 등이 향상됨을 보여주는 연구(Sung, Chang, Chiou, & Hou, 2005; 김민정, 2017)와 동료평가 최종 점수의 산정방식 및 방법에 초점을 맞춘 연구(Conway, Kember, Sivan, & Wu, 1993; Hsia, Huang, & Hwang, 2016)가 주를 이룬다.
한편, 동료평가의 기준은 팀의 집단 역학, 유지력, 응집력, 생산성이며(Ceston, Levine, & Lane, 2008), 이를 참여도, 사전준비, 의사소통, 책임감, 참석률 등으로 구체화하여 리커트 척도로 측정하는 것이 일반적이다(서영진, 서응교, 2019). 이러한 동료평가를 수행할 때 평가의 기준은 일반적으로 교과목의 내용과 교수방법 등에 따라 교수자가 사전에 정하는 것(top-down)이 보편적이다. 그래서 교수자에 따라 평가 기준이 다양하며, 외국문헌에서 사용된 검사도구를 그대로 번안하여 사용하는 경우가 많다0(신태섭, 2018).
이에 본 연구에서는, 학생들이 실제로 어떠한 기준으로 동료를 평가했는지 살펴보고, 이를 교수자의 기준과 비교하고자 한다. 이때 학생들이 활용한 기준을 확인할 수 있는 방안으로, 동료평가 후반부에 학생들이 동료를 판단한 근거에 관하여 자유로운 의견을 제시하도록 하였다. 그리고 이러한 서술형 응답 전체를 텍스트 마이닝(text mining) 기법 중 주제 모델(topic model)을 적용하여 학생들의 동료평가 기준을 탐색하였다.
본 연구의 구체적인 연구 문제는 다음과 같다.
첫째, 동료평가에서 학생들이 가장 중요하게 생각하는 판단 기준은 무엇인가?
둘째, 동료평가의 판단 기준은 동료의 좋은 점과 개선해야할 점에 관하여 동일한가?
셋째, 1차 동료평가와 2차 동료평가에서 학생들의 판단 기준은 동일한가?
2. 잠재디리클레할당(LDA)
2.1 잠재디리클레할당(LDA)의 개념
일반적으로 데이터 마이닝은 컴퓨터 저장장치 및 프로세서의 발달을 기반으로 일상생활에서 얻어지는 다양한 데이터를 기록하고, 저장하여 의미 있는 정보를 추출하여 분석하는 것을 의미한다(Hand, Mannila, & Smyth, 2001). 이 중 텍스트 마이닝이라 하면, 데이터 마이닝 중 활자데이터를 다루는 경우를 특정해서 일컫는 말이다. 따라서 본질적으로 텍스트 마이닝은 대규모의 활자 데이터를 기반으로 의미 있는 정보를 추출하는 작업으로 간주할 수 있다. 특히, 웹에서 활발하게 사용되는 소셜미디어 서비스를 통해 대규모 활자데이터에 접근할 수 있게 되면서 텍스트 마이닝과 관련한 이론⋅실제적 논의가 활발하게 이루어지게 되었다(Aggarwal, & Zhai, 2012).
이러한 텍스트 마이닝 기법에는 LSA(Latent Semantic Analysis), LSI(Latent Semantic Indexing), SVD(Singular Value Decomposition) 등 다양한 기법이 존재하는데, 다양한 텍스트 마이닝 기법 중 주제 모델링 혹은 토픽 모델링(topic modeling)이라고 하는 텍스트 마이닝(text mining)기법이 최근 주목받고 있다. 토픽 모델링은 분석하고자 하는 문서를 기반으로 텍스트에 내재되어 있으나, 직접적인 관측이 불가능한 주제를 분석해낸다는 점에서 데이터 마이닝의 본질적인 목적인 ‘유의미한 패턴 추출’에 잘 부합하는 기법이라고 볼 수 있다.
본 연구에서는 토픽 모델링 중 본래 텍스트 마이닝이 태동하였던 전산학뿐만 아니라, 사회과학 전 분야에서 활발히 사용되는 가장 기본적이고 대표적인 주제 분석 기법인 잠재디리클레할당(Latent Diriclet Allocation; Blei et al., 2003, 이하 LDA)을 기존의 잘 알려진 통계기법에 빗대어 보다 파악하기 용이한 방식으로 제시하고자 한다. 물론, LDA의 세세한 구성요소나 통계적 가정들은 새롭고 복잡한 부분들이 있으나. 모형의 제시의 용이성을 위해 기존의 통계기법과의 유사성에 보다 집중하여 LDA를 기술하였다.
먼저, 개념적으로 LDA는 탐색적 요인분석(exploratory factor analysis)과 유사하다. 탐색적 요인분석의 핵심은 관측가능한 변수를 직접적인 관측이 불가능한 요인으로 설명하는 데 있다. 구체적으로, 요인분석의 초점은 다수의 관측가능한 변수를 보다 적은 수의 요인으로 설명하는 데 있으며, 이러한 설명을 최적으로 해내는 모형 구조를 밝히는 것이 주요한 목적이다. LDA 역시 관측가능한 단어수준의 활자데이터를 관측이 불가능한 주제를 활용하여 보다 간단하게 설명해내는 것을 목적으로 하고 있다. 즉, 탐색적 요인 분석의 요인이 LDA의 주제에 대응되고, EFA의 관측변수가 LDA의 단어에 대응될 수 있을 것이다.
다음으로, LDA는 앞서 설명한 바와 같이, 다수의 단어가 모여 하나의 주제를 구성하고, 다수의 주제가 하나의 문서를 구성하고, 마지막으로 다수의 문서가 하나의 말뭉치를 구성하고 있다(Blei et al., 2003). 그런데 이러한 주제와 문서, 말뭉치가 LDA라고 하는 통계적 모형 하에서 논의되기 위해서는 통계적으로 정교하게 정의되어야할 필요가 있다. 주제는 일반적으로 글에서 중심이 되는 내용으로 정의할 수 있다. LDA에서는 주제의 이러한 특성을 보다 통계적으로 활용하기 위해 다항분포를 활용하여 정의하게 된다. 먼저 다항분포는 범주가 3개 이상인 경우 각 범주의 확률을 나타내는 통계분포로써 x축에는 단어가 제시되고, y축에는 각 단어가 문서에서 나타나는 빈도를 확률적으로 나타내게 된다. 통계적인 용어를 활용하면, 다항분포의 기저(support)는 단어, 확률질량(probability mass)은 문서에서 나타나는 상대적인 빈도를 의미한다고 볼 수 있다. 이를 그림으로 나타내면 [그림 1]과 같다.
![[그림 1]](/upload//thumbnails/kjge-2020-14-6-323-gf1.jpg)
다항분포
실제 LDA에서 위 그림의 x축에 해당되는 단어들은 문서에서 사용된 모든 단어들이다. 예를 들어, 대학생들의 강의 평가에 대한 LDA 연구(곽민호, 민혜리, 김미림, 2019)에서는 약 1,500개 강의에 대해 약 10,000개의 어휘가 활용된 데이터를 분석하였다. 이 경우 주제 분포의 x축에는 10,000개의 단어가 위치하게 되고, y축에는 각 단어의 상대적인 빈도가 제시되게 된다. 단, LDA의 모델 특성상 단어들의 상대적인 빈도는 상위 20~30개 단어에 집중되어 있고, 나머지 단어들의 빈도는 매우 낮거나 0에 가까운 형태로 추정되게 된다. 즉, 위의 예시에서 생각해보면, 약 10,000개 단어 중 20~30개 단어들만 의미 있는 수준의 빈도가 산출되게 되고, 나머지 9,970~9,980개 단어들의 빈도는 0에 가까운 값들로 구성되게 된다.
보다 간단한 예시를 들기 위해 Kwak(2019)의 연구를 활용하였다. 이 연구에서는 말뭉치에 사용된 어휘의 수가 6개로 매우 제한된 가상의 예시를 활용하여 LDA를 설명하면 다음과 같다. 먼저, 가상의 말뭉치를 구성하는 어휘들은 물고기, 파도, 수영, 나무, 등산길, 등반과 같다. 이와 같이 6개의 매우 제한된 어휘로 구성된 말뭉치에 LDA를 적용하여 주제를 추정하게 될 경우, 각각의 주제들은 이 6개의 단어들의 상대적인 빈도에 따라 달라진다. 구체적으로 [그림 2]의 좌측 분포와 같이 나무, 등산길, 등반과 같은 단어들의 확률은 낮고, 물고기, 파도, 수영과 같은 단어의 확률이 높은 경우, 이 주제는 ‘바다’라고 명명할 수 있다. 반면, [그림 2]의 우측에 위치한 분포와 같이 나무, 등산길, 등반 단어가 확률이 높고, 나머지 다른 단어의 확률이 낮은 경우에는 해당 주제를 ‘산’이라고 명명할 수 있다.
![[그림 2]](/upload//thumbnails/kjge-2020-14-6-323-gf2.jpg)
주제별 단어 분포
즉, 주제는 말뭉치에 대한 일종의 거시적인 정보라고 할 수 있다. 이는 말뭉치 전체에 사용된 어휘들의 상대적인 빈도를 나타낸 다항분포이며, 이 분포의 형태를 보고 연구자는 적절한 주제를 명명하게 된다.
이러한 거시적 정보가 말뭉치 전반의 큰 주제에 대한 정보를 제공한다면, 미시적 정보는 개별 문서에 대한 정보를 제공하게 된다. 구체적으로, 미시적 정보는 하나의 문서가 어떠한 주제로 구성되어 있는지에 관한 정보를 제공한다(곽민호, 이진희, 신윤희, 2019).
다음 연구결과는 문서에 대한 정보인데, 이를 앞서 활용한 예시를 활용하여 설명해보면 다음과 같다. [그림 3]의 가장 좌측에 나타난 문서의 경우, 해변, 파도, 수영과 같이 ‘바다’ 주제에서 높은 빈도를 보이는 단어로 주로 이루어진 문서이다. 반면, [그림 3]의 가운데 위치한 문서의 경우 등산로, 등반, 나무와 같이 ‘산’ 주제에서 높은 빈도를 보이는 단어들로 이루어진 문서이다. 마지막으로 [그림 3]의 가장 우측에 있는 문서는 산과 바다에 대한 내용이 약 절반씩 포함되어 있는 문서라고 볼 수 있다.
![[그림 3]](/upload//thumbnails/kjge-2020-14-6-323-gf3.jpg)
문서별 주제 분포와 예시 응답
그러나 이처럼 직접 문서를 읽고 문서의 주제 구성 비율을 파악하는 것은 굉장히 많은 시간과 노동력을 요구하는 일이다. 물론, 지금과 같은 가상의 예시문은 매우 짧기 때문에 이러한 과정의 용이성이 명확하게 드러나지 않지만, 문서의 길이가 200단어 이상, 혹은 500단어 이상이면서, 문서의 수가 10,000개 이상이 되면, 이러한 주제를 파악하는 일은 도전적인 과제임이 분명하다. LDA는 이러한 문서의 주제구성에 대한 정보를 통계적 추정을 통해 제공한다는 장점이 있으며, 본 연구에서는 이를 동료평가의 서술형 응답에 적용하였다.
2.2 잠재디리클레할당(LDA)의 모델 선택⋅평가 및 추정
LDA에서 주제를 결정하는 과정에서는 다음 두 가지 중요한 의사결정이 뒷받침되어야 한다.
첫째, 연구자는 몇 개의 주제를 추출할 것인가에 대해 결정해야 한다. 기존의 유사한 연구방법인 탐색적 요인분석의 경우 역시 연구자가 다양한 준거를 활용하여 요인의 수를 결정한다. 이 때 요인의 수는 특성값(Eigen value)을 활용하거나, 우도기반 지표와 같은 정량적인 방법을 활용하여 결정되기도 하고, 스크리도표(scree plot)와 이론적인 근거를 바탕으로 요인의 수를 설정하는 정성적인 방법도 활용한다. 이처럼 탐색적 요인분석에서 요인의 수를 결정하는 데 다양한 접근법이 존재한다는 것은 이러한 의사결정 과정에 연구자의 주관이 개입된다는 점을 함의하는데, LDA에서도 이러한 유사성이 발견된다.
LDA 역시 주제의 수를 결정하는 데 크게 정량적인 접근과 정성적인 접근방법이 있다. 그 중, 본 연구는 사례가 다양하지 않았기 때문에 정량적인 접근방법을 활용하여 주제의 수를 파악하였다. 가장 일반적인 정량적인 접근 방법은 전산학 분야에서 활발하게 활용되는 혼잡도(perplexity; Grün, & Hornik, 2011)를 적용하는 방법이다. 그러나 혼잡도의 경우 이에 기초하여 추출한 주제의 수와 사람이 직접 읽고 분석하여 추출한 주제 수가 일치하지 않는다는 단점이 있다(Chang, 2010). 따라서 이 연구에서는 정보이론에 근거한 지수를 활용하여 모델평가를 수행하였다. 대표적인 정보이론 근거 지수로는 AIC(Akaike, 1974), BIC(Schwarz, 1978) 등을 제시할 수 있는데, LDA의 경우 전통적인 통계방법론과 달리 모수의 수가 표본크기를 초과한다. 따라서 표본의 수가 모수의 수에 비해 월등히 높은 AIC, BIC와 같은 지수의 활용을 지양하고, 유효모수 수(number of effective parameter; Spiegelhalter, Best, Carlin, & Van der Linde, 2002)에 근거한 DIC (Deviance Information Criterion; Spiegelhalter 외, 2002)를 최적 주제 수 탐색에 활용하였다. DIC는 최근 LDA를 활용한 연구들에서 최적 모델의 수를 결정하는 데 널리 활용되었다(곽민호 외, 2019; Lauderdale, & Clark, 2014; Sizov, 2012). 이러한 DIC를 비롯한 정보기반 지수들은 “모델의 부적합도”를 나타낸다. 즉, DIC의 값이 높을수록 데이터와 모형이 일치하지 않는다는 의미이므로, 일반적으로 DIC 값이 가장 낮은 모형이 최적 모델로 간주되어 선택된다.
둘째, 연구자는 추출된 주제를 적절히 명명해야 한다. 탐색적 요인분석에서도 관측변수와 적재값(loading value)의 조합에 따라 추출한 요인을 잘 설명할 수 있는 적절한 명칭을 부여하게 된다. 이와 마찬가지로 연구자는 LDA에서도 추정된 주제를 보고 적절한 명칭을 부여해야 한다. 보통 명칭을 부여하는 방식은 주제별 단어분포에서 단어를 내림차순으로 정렬하여, 가장 높은 확률을 보이는 단어들을 포괄할 수 있는 명칭을 부여하게 된다.
LDA 역시 다른 통계기법과 마찬가지로 모수를 추정하는 다양한 알고리즘이 존재한다. 먼저, LDA의 모수는 2.1.절에서 설명한 주제별 단어분포(거시적 정보)와 문서별 주제 분포(미시적 정보)이다. 앞선 절에서는 모델 설명의 용이성을 위해 주제가 먼저 추정되고, 문서의 특성이 추정되는 식으로 순서가 존재하는 것처럼 묘사하였으나, 실제 본 연구에서 사용한 알고리즘인 깁스샘플링의 경우, 두 과정이 동시에 반복적으로 번갈아가면서 발생한다고 볼 수 있다. 먼저 주어진 활자 데이터를 단어 수준에서 접근하여, 첫 번째 문서의 첫 번째 단어에 임의의 주제를 부여한다. 이러한 임의의 주제들 중에서 가장 높은 우도(likelihood)를 보이는 주제를 임시적으로 부여하여 주제별 단어분포를 먼저 계산해 낸 후, 그 결과를 바탕으로 문서별 주제 분포를 추정한다. 이렇게 1차적으로 추정된 두 모수에 근거하여 다음 단어에 대해 같은 과정을 반복하고, 최종적으로 문서에 사용된 모든 단어들에 대해 이러한 과정을 반복함으로써 데이터에 가장 부합하는 모형을 산출하게 된다. 다만, 이러한 과정은 확률적이기 때문에 매번 분석을 할 때마다 완벽하게 같은 결과가 산출되지 않는다. 다만, 모형과 데이터가 안정적일수록 강건한(robust) 결과가 산출되게 된다.
3. 연구 방법
3.1 자료수집 및 분석절차
본 연구에서는 2018년 2학기 팀 기반 학습으로 진행되는 강의를 수강한 D대학 학생 57명을 대상으로 동료평가를 2회 진행한 결과를 분석하였다. 동료평가가 시행된 배경은 다음과 같다. 먼저, 학생들이 수강한 교과목은 플립러닝을 활용하였다. 따라서 수업 전 사전학습 형식으로 이러닝을 적용하여, 수강생 모두가 수업관련 특정 시청각자료를 자율적으로 학습하게 하였으며, 이러한 사전학습 내용을 바탕으로 팀을 구성하였다. 팀 구성은 4~5명으로 하여 총 12개 팀이 구성되었다. 구성된 팀에 따라 동일 프로젝트를 진행하였고, 수업 후에는 팀 프로젝트 결과를 바탕으로 팀 발표와 동료평가를 실시하였다. 이처럼 이 연구에 활용된 표집은 그 크기가 제한되어 있고 특정 대학의 한 학기 자료를 바탕으로 하였다는 점에서 통계적으로 일반화하기는 어렵다. 그러나 아래 기술할 D대학의 수강생 특성 등에 비추어 볼 때, 대학에서 일반적으로 개설되는 교양 교과목의 특성을 적절히 반영하였다고 간주하고, 연구결과의 제한적인 일반화를 유도할 수 있을 것으로 보인다.
인구통계학적 특성에 따른 결과는 <표 1>에 제시되어 있다. 구체적으로 보면, 먼저, 성별의 경우, 남학생은 17명(29.2%), 여학생은 40명(70.8%)으로 여학생들의 비율이 높았다. 학년의 경우, 1학년부터 4학년까지 전반적으로 분포되어 있었으나, 1학년 25명(43.9%), 2학년 20명(35.0%)으로 저학년이 많은 비중(78.9%)을 차지하였다. 소속 학과는 상경대학을 중심으로(50.9%), 예술디자인대학(8.8%), 음악대학(8.8%)의 학생들 비중이 높았다. 이 외에도 총 10개의 다양한 전공의 학생들이 본 연구의 대상이 되었다.

연구 대상의 특성
자료수집을 포함한 연구진행 단계는 곽민호, 신윤주, 이진희(2019)에서 활용된 연구방법 및 단계 요약표를 일부 변경하여 <표 2>에 재구성하였다.

연구 방법 및 단계 요약
연구방법 및 단계 요약은 크게 4단계로 이루어진다. 먼저, 자료수집 단계는 일반적으로 다른 양적연구에서 이루어지는 방식과 유사하다. 앞서 언급한 연구참여자들을 대상으로 인구통계학적인 특성을 포함한 일련의 설문 및 동료평가를 실시한 결과를 수집하는 단계이다. 다음으로 데이터 전처리 단계이다. 이 단계의 경우 먼저 불성실 응답이나 결측 문항 처리에 대한 판단을 수행하다는 점에서 기존의 전통적인 양적연구방법론의 접근방법과 유사하나, 텍스트 마이닝 기법을 적용하는 경우 몇 가지 특징적인 처리과정이 추가적으로 수행하여야 하므로, 절을 분리하여 다음 절에 기술하였다.
3.2 자료 전처리 과정
본래, 선행연구(Boyd-Graber, Mimno, & Newman, 2014; Kwak, 2019)에서 제안하고 있는 텍스트 마이닝의 전처리 과정은 3가지이며, 크게 1) 토큰화(tokenization), 2) 정규화(normalization), 3) 불용어(stopword) 제거 순으로 이루어져 진다. 토큰화의 경우 분석이 가능한 최소형태 정보로 문서를 가공하는 단계인데, 간단히 띄어쓰기와 단어를 기준으로 이루어진다고 보면 편리하다. 예를 들어, 앞서 예시로 제시하였던 문장인 “무엇이든 상상할 수 있는 사람은 무엇이든 만들어낼 수 있다.”를 활용하여 토큰화를 적용하면, 하나의 정보였던 위 문장은 “무엇이든”, “상상할”, “수”, “있는”, “사람은”, “무엇이든”, “만들어낼”, “수”, “있다”와 같이 9개의 분절된 정보로 나타내어질 수 있다. 다음으로 정규화단계이다. 정규화단계는 단어들을 가장 기본적인 형태로 변환하는 것을 의미한다. 예를 들어, 문서에 “increased”, “increasing”과 같은 단어들이 사용되었다면, 두 단어들은 같은 의미를 가지는 “increase”로 변환할 수 있다. 마지막으로 불용어 제거의 경우, 불용어라고 정의되는 단어들은 문서에서 제거하는 단계이다. 불용어라 함은 “입니다”, “습니다”와 같이 문장의 주제와 무관하게 빈번하게 등장하는 단어들은 의미한다.
다만, 불용어를 선정하는 과정은 연구자의 주관이 개입됨과 동시에 말뭉치의 특성 역시 반영하여야 한다. 예를 들어, “습니다.” 라는 단어는 일반적인 말뭉치에서는 불용어로 간주할 수 있지만, 경우에 따라 특정 주제의 주요한 구성요소가 되는 단어가 될 수 있다. 반대로, “의사”라고 하는 단어는 일반적으로 불용어라고 간주되지 않는다. 그러나 말뭉치가 의약분야의 문서에서 표집 되었다면, 대부분의 문서에서 의사라는 단어가 포함되기 때문에 특정주제를 구성하는데 주요한 기능할 할 가능성은 낮다. 즉, 불용어의 선정은 주관적이고, 문서 내 단어가 차지하는 위상에 따라 바뀐다. 이러한 과정을 보다 통계적으로 적용한 방법이 바로 TF-IDF(Term frequency-inverse document frequency; Grün, & Hornik, 2011; Manning, Raghavan, & Schutze, 2008) 점수를 활용하는 방법이다.
이 TF-IDF 점수는 기본적으로 특정 단어의 빈도를 나타내는 TF 점수와 문서 전반적으로 특정 단어의 노출 빈도 역수인 IDF 점수의 곱으로 나타낸다. 즉, 비록 문서 내 특정 단어의 빈도가 높다하더라도, 이러한 높은 빈도가 특정 문서에 제한되어 있지 않고, 다양한 문서에 전반적으로 나타나게 될수록 TF-IDF 점수는 감소하게 된다.
이렇게 TF-IDF 점수를 활용하여 불용어를 선정하게 되는 경우, TF-IDF의 기준 점수가 필요한데, 이에 대한 구체적인 가이드라인은 제시되지 않았다. 물론, TF-IDF 기준 중위수를 사용해야한다는 R패키지 가이드라인(Grün, & Hornik, 2011)이 존재하나, 이를 그대로 적용할 경우 전체 사용된 어휘의 절반이 분석 시 불용어로 간주되므로, 말뭉치의 크기가 작고, SNS에 무작위로 작성된 글과 달리 시험이나 설문과 같은 특정한 목적에 대한 응답으로 어휘 수가 제한된 말뭉치에서는 사용하기 적절하지 않은 점이 있다. 다만, 텍스트 마이닝에 대한 선행연구(Manning, Raghavan, & Schutze, 2008)에서는 일반적으로 30개 정도의 불용어 선정을 권장하고 있으므로, TF-IDF 점수를 근거로 가장 점수가 낮은 단어를 약 30개를 선정하여 불용어로 간주하여 분석하였다.
위에 서술한 토큰화, 정규화, 불용어 처리와 같은 자료 전처리 과정들은 LDA 분석의 기초가 되는 단어-문서 행렬(term-document matrix)의 변환과 깊은 관련이 있다. 특히, 정규화과정과 불용어 제거 과정은 각각 행렬의 차원을 축소하고 특정 행이나 열에 요소값이 과대하게 부여되는 것을 방지하여 보다 명확한 주제 추출이 가능해진다는 점에서 중요한 단계라고 볼 수 있다.
다만, 위 과정은 영어를 대상으로 수행한 텍스트 마이닝 연구에서 제안하고 있는 접근법이다. 한국어의 경우 시제와 문법 등에 따라 나타나는 어형변화가 영어와 달라 위 과정을 그대로 적용하는 데는 명확하지 않은 점이 있다. 따라서 본 연구에서 기존의 선행연구(최정아, 곽민호, 2019; 곽민호 외, 2019)에서 제안한 방법들을 종합하여, 어간추출과 불용어 제거 두 단계로 구성하였다. 어간추출은 앞서 언급한 정규화와 유사한데, 문서에서 활용된 단어 중에서 의미를 담고 있는 어간 부분만을 KoNLP(Jeon & Kim, 2016) 패키지를 활용하여 분석에 활용하였다.
4. 연구 결과
4.1 기술통계
이 연구에서는 총 여섯 개의 말뭉치를 분석하였고, 각 말뭉치의 의미와 문서 수, 어휘 수, 단어 수, 문서 평균 길이와 같은 기술통계는 <표 3>에 제시하였다. 먼저, 첫 번째와 두 번째 연구문제인 동료평가에서 학생들이 가장 중요하게 생각하는 판단 기준이 무엇인지 탐색해보고, 동료의 좋은 점과 개선점의 판단 기준이 있는지 차이점을 분석하기 위해 1⋅2차 통합 좋은 점 말뭉치와 1⋅2차 통합 개선점 말뭉치를 활용하였다. 다음으로, 세 번째 연구 문제로 1차 동료평가와 2차 동료평가에서 학생들의 판단 기준의 동일성을 파악하기 위해 1차 좋은 점 말뭉치, 1차 개선점 말뭉치, 2차 좋은 점 말뭉치, 2차 개선점 말뭉치 4개의 말뭉치를 분석하였다. 구체적으로 보면, 총 57개 문서가 활용되었고, 1⋅2차 통합 좋은 점 말뭉치의 경우 472개의 어휘, 개선점의 경우 371개 어휘가 활용되었다. 또한, 단어 수는 각각 1,790개와 1,143개로 나타났다. 문서 평균 길이의 경우, 좋은 점은 31.40 단어, 개선점이 20.05 단어로 구성된 것으로 나타났다.

말뭉치 기술통계
4.2 모델 및 사전분포의 선택
이 연구에서는 선행연구에서 제안한 DIC를 적용하였는데, 모두 3주제 모델이 적절한 것으로 제안되었다. 이처럼 최적 모델을 선택하기 위해서는 정보기반 지수(information based index)가 일반적으로 사용된다. 다만, LDA의 경우, 최적 주제 수 설정에 대한 실증 및 이론적인 연구가 부족한 실정이다. 특히, 본 연구에 사용된 샘플 크기가 일반적으로 LDA에서 사용되는 샘플크기에 비해 매우 작기 때문에 주제 수 선택에 신중해야할 필요가 있다.
이를 위해 이 연구에서는 주제 수가 4개 이상인 경우(5, 6, 7, 8, 9, 10 주제까지)에도 분석을 수행하였는데, 4주제부터 동일한 주제가 추출되거나, 주제 간 내용이 심하게 겹치는 현상이 관측되었다. 구체적으로, 4주제 모델부터 주제 구조가 유사한 주제들이 추출되거나, 특정 주제 구조에 해당되는 단어 비율이 매우 적어(5% 미만), 해석에 적절하지 않았다. 따라서 <표 4>에 보고된 DIC를 기반으로 모델을 선택하되, 해석에의 용이성(interpretability)도 고려하여 주제를 선택하였다.
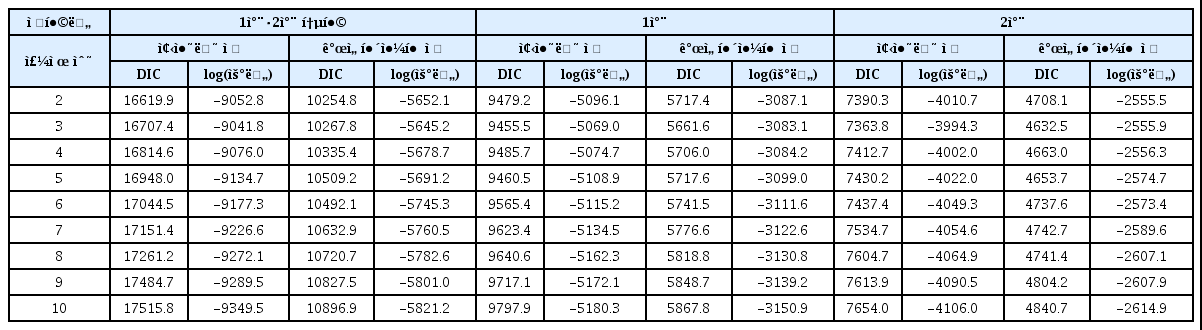
동료평가 말뭉치별 모형 적합도
4.3 분석별 주제 모형
첫 번째 연구문제인 동료평가에서 학생들이 가장 중요하게 생각하는 판단 기준을 파악하고, 두 번째 연구문제인 그 판단 기준들이 좋은 점과 개선해야할 점에 대해 동일한지 적용되는지 여부를 파악하기 위해, 동료평가 응답 중 좋았던 점과 개선해야할 점 말뭉치에 대한 주제 분석을 수행하였다. 두 연구문제의 핵심이 보다 안정적이고, 보편적인 상황에서의 동료평가 기준을 탐색하는 데 있으므로, 이 분석에 활용된 좋았던 점과 개선하여야할 점 말뭉치는 1차와 2차 동료평가를 통합하여 활용하였다.
먼저, 동료평가 응답 중 좋았던 점에 대한 주제 분석을 수행한 결과는 [그림 4]와 같다. 구체적으로, [그림 4]를 보면, 좋았던 점에 대해 분석한 세 가지 주제의 단어구름을 나타내고 있다. 단어의 크기가 크고 중심에 위치할수록 각 주제 내에서의 상대적인 중요성 및 빈도가 높기 때문에 이를 고려하여 주제명을 부여하였다. 예를 들어, [그림 4]의 가장 왼쪽의 첫 번째 주제의 경우, ‘의견’, ‘팀원’, ‘제시’와 같은 단어 들이 주로 제시되고 있으므로, 이를 포괄할 수 있는 주제의 명칭으로 ‘의사소통능력’을 부여하였다. 다음으로, 두 번째 주제의 경우, ‘적극’, ‘의견’, ‘분위기’ 등의 단어들이 상대적으로 높은 빈도를 보인 것으로 나타난다. 이러한 단어들을 포함할 수 있는 주제 명칭으로 ‘적극적인 태도’를 부여하였다. 마지막으로, 가장 오른쪽에 있는 주제의 경우, ‘발표’, ‘전공’, ‘결과’와 같은 단어들이 상대적으로 중요성이 높은 단어로 났기 때문에 ‘팀 활동 능력’ 으로 주제명을 결정하였다.
![[그림 4]](/upload//thumbnails/kjge-2020-14-6-323-gf4.jpg)
1차⋅2차 통합 좋았던 점 주제 분석 결과
또한, 전체 말뭉치에서 각 주제별로 단어들의 분포 정도를 파악하기 위해 <표 5>을 제시하였다. <표 5>에는 주제별 단어 수와 비율이 제시되어 있다. 구체적으로 설명하면, 1차⋅2차 통합 좋았던 점에 대한 문서에 활용된 단어의 수는 1,790개이며, 이 중 적극적인 태도’ 주제 관련 단어가 가장 높은 비율(41.23%)을 차지하는 것으로 보인다. 또한, 다음으로는 ‘의사소통 능력’ 주제 관련 단어가 차지하는 비율(40.89%)이 높은 것으로 나타났다. 마지막으로, ‘수업관련 실제적 활동’과 관련된 단어의 수가 가장 낮은 비율(17.88%)을 보였다.

1차⋅2차 통합 좋았던 점 주제별 단어 수 및 비율
이어서, [그림 5]는 동료평가에서 개선해야할 점에 대한 응답을 분석한 결과이다. 구체적으로, 개선해야 할 점에 대해 분석한 세 가지 주제의 단어구름을 나타내고 있다. 역시, 단어의 크기가 크고 중심에 위치할수록 각 주제 내에서의 상대적인 중요성 및 빈도가 높기 때문에 이를 고려하여 주제명을 부여하였다. 예를 들어, [그림 5]의 가장 왼쪽의 첫 번째 주제의 경우, ‘의견’, ‘자신’, ‘팀원’와 같은 단어들이 주로 제시되고 있으므로, 이를 포괄할 수 있는 주제 명칭으로 ‘의사소통능력 부재’를 부여하였다. 다음으로, 두 번째 주제의 경우, ‘적극’, ‘의견’, ‘소극’ 등의 단어들이 상대적으로 높은 빈도를 보인 것으로 나타난다. 이러한 단어들을 포함할 수 있는 주제 명칭으로 ‘소극적인 태도’를 부여하였다. 마지막으로, 가장 오른쪽에 있는 주제의 경우, ‘없다’, ‘팀’, ‘활동’과 같은 단어들이 상대적으로 중요성이 높은 단어로 나타났다. 이 경우 “특별히 없음” 으로 주제명을 결정하였다.
![[그림 5]](/upload//thumbnails/kjge-2020-14-6-323-gf5.jpg)
1차⋅2차 통합 개선해야할 점 주제 분석 결과
또한, 전체 말뭉치에서 각 주제별로 단어들의 분포 정도를 파악하기 위해 <표 6>을 제시하였다. <표 6>에는 주제별 단어 수 및 비율이 제시되어 있다. 구체적으로 설명하면, 1차와 2차가 통합된 개선해야할 점에 대한 문서에 활용된 단어의 수는 1,143개이며, 이 중 소극적인 태도’ 주제 관련 단어가 가장 높은 비율(40.86%)을 차지하는 것으로 보인다. 다음으로, ‘의사소통능력 부재’ 주제 관련 단어가 높은 비율(34.30%)을 차지하는 것으로 나타났다. 마지막으로, ‘특별히 없음’과 관련된 단어의 수가 가장 낮은 비율(24.85%)을 보였다.

1차⋅2차 통합 개선해야할 점 주제별 단어 수 및 비율
위 두 1⋅2차 통합 좋았던 점과 개선해야할 점의 말뭉치 분석 결과를 요약해 보면 다음과 같다. 먼저, 동료평가에서 학생들이 가장 중요하게 생각하는 판단 기준의 경우, 좋았던 점에서는 ‘적극적인 태도’ 관련 주제가 가장 빈번하게 활용되었고, 다음으로 ‘의사소통능력’, 마지막으로 ‘수업관련 활동’인 것으로 나타났다. 개선해야할 점에서는 중요하게 생각하는 판단 기준은 ‘소극적인 태도’, ‘의사소통능력의 부재’, ‘특별히 없음’으로 나타났다. 또한, 좋았던 점과 개선 점에 대한 판단 기준을 비교해 보면 두 경우 모두 적극성과 의사소통 능력을 중요한 판단 기준으로 보는 것으로 나타났다. 다만, 좋았던 점에서 비율은 낮았지만, 제시되었던 수업관련 활동의 경우, 개선해야 할 점에서는 뚜렷한 주제로 구성되어 제시되지 않았다.
마지막으로, 세 번째 연구문제였던 1차 동료평가와 2차 동료평가에서 학생들의 판단 기준이 동일한지 여부를 판단하기 위해 1차 평가와 2차 평가에서의 주제구조의 차이점을 분석하였다. 먼저, 좋았던 점에 대해 1차 동료평가 결과의 2차 동료평가 결과를 분석하였다. 분석 결과 1차 시기와 2차 시기 피드백의 주제구조는 1차⋅2차 통합 결과와 유사한 주제구조를 보였다. 구체적으로는 [그림 6]과 [그림 7]에 제시되어 있다. 먼저, [그림 6]은 1차 시기에 좋았던 점에 대한 말뭉치를 분석한 결과를 제시하고 있다. 1차 시기 주제 구조 결과는 두 차시를 통합하여 분석한 [그림 4]와 같이 ‘의사소통 능력’, ‘적극적인 태도’, ‘수업관련 실제적 활동’으로 나타났다.
![[그림 6]](/upload//thumbnails/kjge-2020-14-6-323-gf6.jpg)
1차 시기 좋았던 점 주제 분석 결과
![[그림 7]](/upload//thumbnails/kjge-2020-14-6-323-gf7.jpg)
2차 시기 좋았던 점 주제 분석 결과
다음으로, 2차 시기 좋았던 점에 대한 주제 분석 결과는 [그림 7]에 제시되어 있다. 2차시기의 결과는 앞서 [그림 4]에 제시되었던 1차, 2차 통합 말뭉치에 대한 주제분석 결과 및 [그림 6]에서 나타난 1차 시기 좋았던 점에 대한 주제 분석 결과와 같은 주제 구조를 나타냈다. 구체적으로, ‘의사소통 능력’, ‘적극적인 태도’, ‘수업관련 실제적 활동’로 나타났다.
이처럼 주제 구조 자체는 유사하였으나, 각 주제에 해당되는 단어 수의 비율 차이가 있었다. 이러한 차이를 보다 통계적으로 판단하기 위해 기술통계 결과와 함께 카이제곱검정 결과를 <표 7>에 제시하였다. 먼저, 1차 시기의 주제구조를 파악해 보면, ‘적극적인 태도’ 관련 주제에 해당되는 단어가 368개 단어(37.21%)로 가장 많이 활용되었다. 다음으로, ‘의사소통 능력’ 관련 주제에 해당되는 단어가 344개 단어(34.78%)로 활용되었다. 마지막으로, ‘수업관련 실제적 활동’ 주제에 해당하는 단어가 277개 단어(28.01%)로 가장 적은 비율로 활용되었다. 이와 유사하게 2차 시기 동료평가의 좋았던 점에 대한 내용도 ‘적극적인 태도’ 관련 주제에 해당되는 단어가 384개 단어(46.32%)로 가장 많이 활용되었고, ‘의사소통능력’ 관련 주제에 해당되는 단어는 267개 단어(32.21%)로 두 번째로 많이 활용되었다. ‘수업관련 실제적 활동’ 관련 주제는 1차 시기 동료평가 결과와 마찬가지로 178개 단어(21.47%)가 활용되어 가장 낮은 비율을 보였다.

1차⋅2차 좋았던 점 주제별 단어 수 및 비율 차이 검정
이처럼 1차 시기 동료평가 결과와 2차 시기 동료평가 결과의 주제구조 및 빈번하게 활용된 주제의 비율 순서가 모두 같았으나, 주제별 비율 구성에 대해서는 차이를 보였기 때문에 이를 통계적으로 검정하기 위해 카이제곱 검정을 수행하였다. 검정 결과 2차 시기 동료평가의 주제구조의 비율과 1차 시기 동료평가의 주제구조 비율이 유의미하게 다른 것으로 나타났다(χ2 =17.640(df=3), p<.001). 즉, 1차 시기 동료평가 결과에 비해 2차 시기 동료평가 결과에서 ‘적극적인 태도’ 관련 주제에 대한 언급이 더 많아졌다.
이어서, 개선해야할 점에 대한 분석 결과 1차 시기와 2차 시기의 주제구조는 통합 결과와 유사한 세 가지 주제구조를 보였다. 구체적으로는 [그림 8]과 [그림 9]에 제시되어 있다. 먼저, [그림 8]은 1차 시기에 개선해야할 점에 대한 말뭉치를 분석한 결과를 제시하고 있다. 1차 시기의 주제 구조 결과는 두 차시를 통합하여 분석한 [그림 5]와 같이 ‘의사소통 능력 부재’, ‘소극적인 태도’, ‘특별히 없음’ 으로 나타났다.
![[그림 8]](/upload//thumbnails/kjge-2020-14-6-323-gf8.jpg)
1차 개선해야할 점 주제 분석 결과
![[그림 9]](/upload//thumbnails/kjge-2020-14-6-323-gf9.jpg)
2차 개선해야할 점 주제 분석 결과
다음으로, 2차 시기 개선해야할 점에 대한 주제 분석 결과는 [그림 9]에 제시되어 있다. 2차시기의 결과는 앞서 [그림 5]에 제시되었던 1차, 2차 통합 말뭉치에 대한 주제분석 결과 및 [그림 8]에서 나타난 2차 시기 개선해야할 점에 대한 주제 분석 결과와 같은 주제 구조를 나타냈다. 구체적으로, ‘의사소통 능력 부재’, ‘소극적인 태도’, ‘특별히 없음’ 으로 나타났다.
이처럼 개선해야할 점에 대한 1차 시기 동료평가 결과와 2차 시기 동료평가 결과의 주제구조는 유사하였으나, 주제별 비율 구성에 대해서는 차이를 보였기 때문에 이를 통계적으로 검정하기 위해 카이제곱 검정을 수행하였다(<표 8> 참조)

1차⋅2차 개성해야할 점 주제별 단어 수 및 비율 차이 검정
먼저, 1차 시기의 주제구조를 파악해 보면, ‘소극적인 태도’ 관련 단어가 262개로 가장 높은 비율(41.72%)로 활용되었다. 다음으로, ‘의사소통능력 부재’에 해당되는 단어가 214개로 두 번째 높은 비율(34.08%)로 활용되었다. 마지막으로, ‘특별히 없음’에 해당하는 단어가 152개 단어로 가장 낮은 비율(24.20%)로 활용되었다.
이와 달리, 2차 시기 동료평가의 개선해야할 점에 대한 내용의 경우 ‘의사소통능력부재’ 관련 단어가 213개로 높은 비율(38.80%)로 활용되었고, ‘소극적인 태도’ 관련 단어는 190개로 두 번째 높은 비율(34.61%)로 활용되었다. 마지막으로 ‘특별히 없음’ 관련 단어가 146개 활용되어 가장 낮은 비율(26.59%)을 보였다.
이러한 비율 차이를 통계적으로 검정하기 위해 카이제곱 검정을 수행하였다. 검정 결과 2차 시기 동료평가의 주제구조의 비율과 1차 시기 동료평가의 주제구조 비율이 유의미하게 다른 것으로 나타났다(χ2 =6.318(df=3), p<.001). 즉, 1차 시기 동료평가 결과에 비해 2차 시기 동료평가 결과에서 ‘의사소통능력 부재’와 관련된 내용이 더욱 부각되는 것으로 나타났다.
이를 바탕으로 연구결과를 정리하면, 1차⋅2차 통합 동료평가 결과의 경우, 적극성을 모두 가장 중요한 판단 기준으로 삼았다. 그러나 1차와 2차로 분리하여 동료평가 결과를 보면, 좋았던 점과 개선해야할 점에서 학생들이 사용하는 평가의 기준이 다르다. 먼저, 좋았던 점과 관련된 동료평가의 경우 1차와 2차 모두 적극성이 중요한 역할을 하였고, 이는 2차 시기로 갈수록 더욱 중요해지는 양상을 보였다. 반면, 개선해야할 점의 경우, 1차 시기에서는 좋았던 점에 대한 평가와 같이 적극성이 강조되었으나, 2차 시기 동료평가에서는 오히려 적극성에 대한 단어의 빈도가 감소하고, 의사소통능력 부재와 관련된 단어의 언급이 더 증가하였다.
5. 결론 및 논의
COVID-19로 야기된 팬더믹 현상으로 인해 대다수 대학이 비대면 교육으로 전환을 시도하고 있다. 또한, 이러한 팬더믹 현상이 쉽게 잦아들지 않을 것으로 판단되면서, 비대면 교육은 일시적인 현상이라기보다 대학 교양교육의 중요한 한 축으로 자리 잡을 가능성이 매우 높아 보인다. 그리고 최근 비대면 교육의 전반적 시행에 의해 대학은 ‘고등교육의 비용과 가치’에 대한 심각한 질문들을 답해야 하는 상황에 놓였다(Pohle, 2020. 8.28.). 이러한 상황에서 온라인 교육과 오프라인 교육을 합친 블렌디드 러닝의 가치는 이전보다 높아졌다고 볼 수 있다. 특히, 블렌디드 러닝은 단순히 팬더믹으로 강제된 비대면 교육 때문만이 아니라, 수업의 효율과 학습의 효과를 높인다는 측면에서 이미 연구가 진행되고 있던 분야라는 점에서 더욱 매력적인 교수학습법이다.
그러나 이미 교양교육에서 큰 비중을 차지하고 있는 팀 프로젝트 영역(백승수, 2017)이 블렌디드 러닝을 포함하는 비대면 교육으로 전환되었을 때, 팀 관리 측면에서 교수자와 학습자 모두 부담스러운 점이 있다. 이 경우, 동료평가가 비대면 상황에서의 팀 활동을 평가하고 지원하는 효과적인 도구로 활용될 수 있을 것이다.
이에 본 연구는 팀 기반 학습이 일어나는 수업 현장에서 진행될 동료평가를 보다 정교하게 하는 데 기여하고자 수행되었다. 이를 위해 D 대학 57명 학생들을 대상으로 팀 활동을 수행한 강의를 대상으로 동료평가 결과를 수집하였고, 서술형 응답 전체에 LDA를 적용⋅분석하여 다음 연구문제를 탐색하였다. 먼저 동료평가의 판단 기준을 탐색해 보고, 이러한 기준이 좋은 점과 개선해야할 점에 대한 평가에서 동일하게 적용되는지 여부를 탐색하였다. 나아가, 1차와 2차에 걸쳐 동료평가를 시행하였을 때 동료평가의 기준이 변화되는 지 여부 역시 파악하였다.
연구 결과를 보면, 좋았던 점에 대한 동료평가의 경우, ‘적극적인 태도’가 가장 중요한 판단 기준으로 작용하는 것으로 보였다. 다음으로 ‘의사소통능력’, 마지막으로 ‘수업관련 활동’이 동료평가와 관련하여 적용되는 기준인 것으로 나타났다. 개선해야할 점에서도 역시 중요하게 생각하는 판단 기준은 ‘소극적인 태도’였다. 다음으로, ‘의사소통능력의 부재’, ‘특별히 없음’ 순으로 나타났다. 이를 통해 동료평가에서 개선해야할 점과 좋은 점에서 공통적으로 강조되고 있는 영역은 적극성과 관련된 태도인 것으로 나타났다.
그러나 1차와 2차 시기 동료평가 결과를 분리한 분석은 조금 다른 결과를 제시하였다. 먼저, 좋았던 점에 대한 동료평가의 경우 1차 시기보다 2차 시기에서 보다 적극성이라는 판단 기준이 더욱 강조되는 양상을 보였다. 그러나 개선해야 할 점의 경우, 1차 시기와 달리 2차 시기에서는 적극성보다 의사소통능력이 보다 중요한 동료평가 기준으로 적용된 것으로 보였다.
즉, 팀 활동의 초반에는 팀원을 평가할 때 적극성에 대한 내용이 많이 언급되는데, 후반부에서는 이러한 경향이 더욱 강하져서, 팀원의 장점을 평가할 때 ‘적극성’이라는 점을 주로 언급하는 것으로 보였다. 반면에, 개선해야 할 점에 대한 동료평가의 경우 팀 활동의 초반에는 적극성을 강조하며, 좀 더 적극적인 활동이 필요하다는 점이 가장 많이 논의가 되었으나, 팀 후반부로 진행됨에 따라 적극성보다는 의사소통능력에 대한 개선이 필요하다는 언급이 더욱 많아지는 것으로 나타났다. 이는 팀 활동이 진행됨에 따라 학생들 간 라포(rapport)가 형성되면서 자연스럽게 보다 적극적으로 활동하게 되지만, 의사소통 능력의 경우 적극성만큼 자연스럽게 증가한 것으로는 보이지 않는다.
이러한 연구 결과를 바탕으로 교수자는 팀 활동 이전에 학생들에게 동료평가에서 좋은 결과를 얻기 위해서는 매사 적극적인 태도를 보이는 것이 중요하다는 점을 강조할 필요가 있다. 또한, 팀 활동이 진행될수록 팀 내 의사소통을 활발히 하는 것이 성공적인 팀 프로젝트 완수에 필수적이라는 점을 부각시켜 긍정적인 팀 활동을 유도해야할 것으로 보인다.
후속연구로 보다 다수의 학생을 대상으로 동일 연구를 수행한다면 LDA의 장점이 더욱 부각될 것으로 보인다. 또한, 이러한 동료평가의 주제 분석 결과와 기존 리커트 척도 결과를 비교하여 분석하는 연구 역시 동료평가의 기준과 실제 동료평가 결과에 대한 관계를 파악하는 데 기여할 수 있을 것으로 보인다. 나아가, 동료평가 수행자의 인구통계학적 특성에 따라 평가 기준 및 결과가 달라지는 것에 관한 연구를 진행하여, 서술형 동료평가의 기준이 성별이나 나이, GPA 수준, 해당 과목 평점 등과 같은 인구통계학적 변인 및 배경 변인 따라 차이가 있다는 경험적 증거를 제시할 수 있을 것으로 보인다.